- genevb's home page
- Posts
- 2025
- 2024
- 2023
- 2022
- September (1)
- 2021
- 2020
- 2019
- 2018
- 2017
- December (1)
- October (3)
- September (1)
- August (1)
- July (2)
- June (2)
- April (2)
- March (2)
- February (1)
- 2016
- November (2)
- September (1)
- August (2)
- July (1)
- June (2)
- May (2)
- April (1)
- March (5)
- February (2)
- January (1)
- 2015
- December (1)
- October (1)
- September (2)
- June (1)
- May (2)
- April (2)
- March (3)
- February (1)
- January (3)
- 2014
- 2013
- 2012
- 2011
- January (3)
- 2010
- February (4)
- 2009
- 2008
- 2005
- October (1)
- My blog
- Post new blog entry
- All blogs
Condor job Resident Memory comparisons
Updated on Tue, 2025-07-22 13:35. Originally created by genevb on 2025-07-22 12:23.
We had some jobs getting held by condor on Alma9 for exceeding memory usage, so I investigated a little.
For this study, I used 12 jobs from Run 24 pp200 TPC SpaceCharge calibration work. These jobs require several hundred MB of memory at the finish of the chain for just a few seconds. These jobs never triggered condor holds in the past. I ran these 12 jobs in 4 environments, all using 64-bit optimized code from NFSv4 (should be identical):
There is also a ResidentSetSize number reported by condor_q -l, but it seems to be the allocation at any given time, as it is always larger than ResidentSetSize_RAW, and is a round number (e.g. 2000 MiB).
It is clear that ResidentSetSize_RAW is only further updated by condor every ~12 minutes, even though I recorded the value every ~1-2 seconds. This results in not necessarily capturing the true RSS memory at the termination/holding of a job.
It is important to note that all of the jobs in environment 3 were eventually held by condor, and none of the other jobs were held! This is particularly interesting for the jobs on SL7 nodes in that their reported MemoryProvisioned was (by default) 1536 MiB (compared to 2000 MiB by default for the Alma9 jobs), implying no enforcement of the memory limit in their case. Jérôme has offered the possible explanation that the condor instance running on the SL7 farm allows additional memory use if it isn't in demand by other jobs on the node, while the version on the Alma9 farm may be strict regardless of anything else on the node. The final recorded value of ResidentSetSize_RAW persisted in the output of condor_q -l for the Alma9 held jobs indefinitely until I removed the condor jobs, so the final time recorded for environment 3 jobs is artificial here for my cut-off. The other jobs all have their data end in time when the jobs completed on their own.
One last point I want to make is that the jobs may not necessarily have landed on the same type (speed) of nodes (I did not require this), so one should not draw conclusions from the time duration that a job ran in one environment versus another.
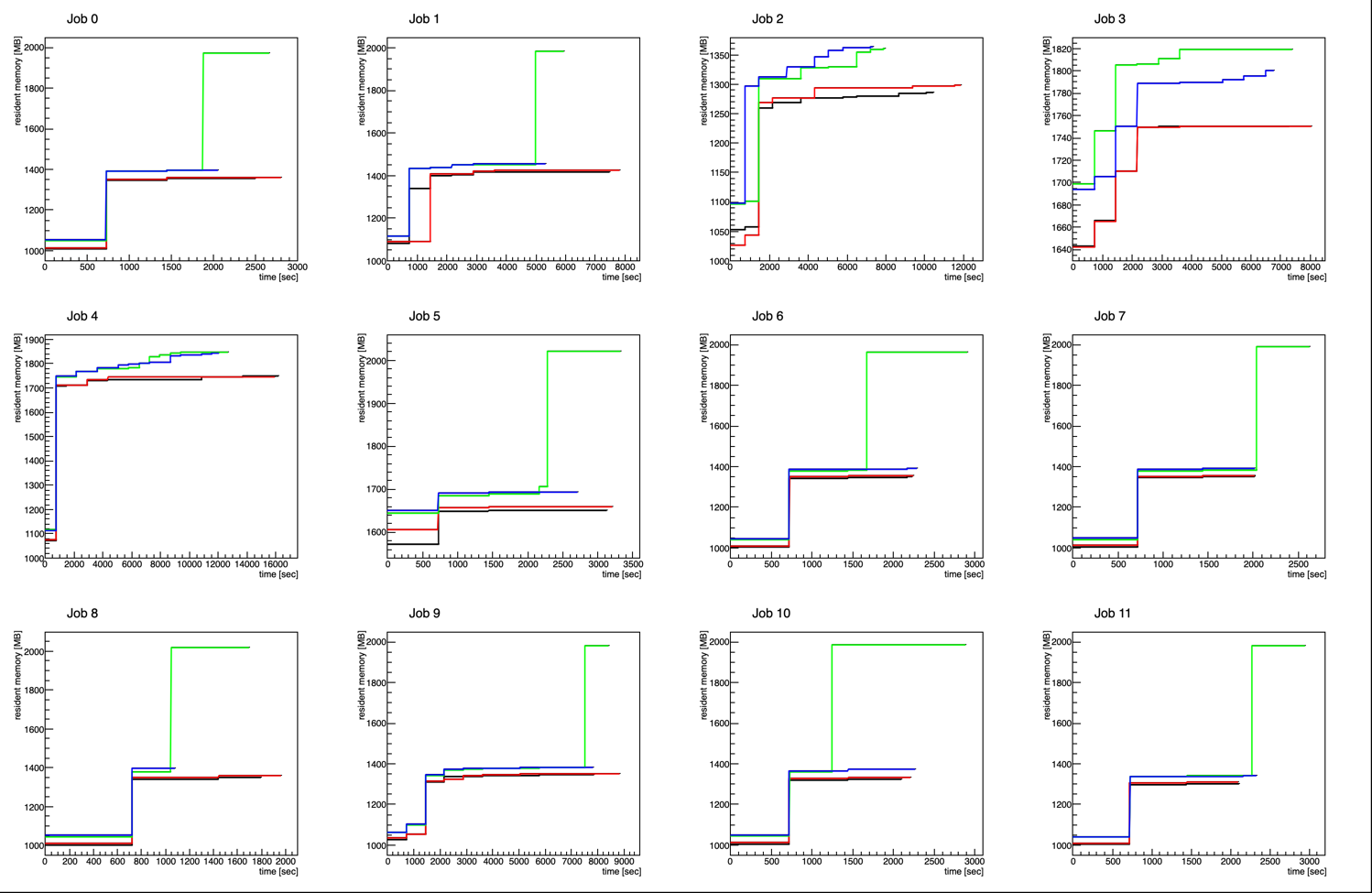
Some observations:
For this study, I used 12 jobs from Run 24 pp200 TPC SpaceCharge calibration work. These jobs require several hundred MB of memory at the finish of the chain for just a few seconds. These jobs never triggered condor holds in the past. I ran these 12 jobs in 4 environments, all using 64-bit optimized code from NFSv4 (should be identical):
- BLACK : native SL7 jobs
- RED : SL7 containers on SL7 nodes
- GREEN : SL7 containers on Alma9 nodes with the (currently) default memory limit of 2000 MiB
- BLUE : SL7 containers on Alma9 nodes with a raised memory limit of 3500 MiB
There is also a ResidentSetSize number reported by condor_q -l, but it seems to be the allocation at any given time, as it is always larger than ResidentSetSize_RAW, and is a round number (e.g. 2000 MiB).
It is clear that ResidentSetSize_RAW is only further updated by condor every ~12 minutes, even though I recorded the value every ~1-2 seconds. This results in not necessarily capturing the true RSS memory at the termination/holding of a job.
It is important to note that all of the jobs in environment 3 were eventually held by condor, and none of the other jobs were held! This is particularly interesting for the jobs on SL7 nodes in that their reported MemoryProvisioned was (by default) 1536 MiB (compared to 2000 MiB by default for the Alma9 jobs), implying no enforcement of the memory limit in their case. Jérôme has offered the possible explanation that the condor instance running on the SL7 farm allows additional memory use if it isn't in demand by other jobs on the node, while the version on the Alma9 farm may be strict regardless of anything else on the node. The final recorded value of ResidentSetSize_RAW persisted in the output of condor_q -l for the Alma9 held jobs indefinitely until I removed the condor jobs, so the final time recorded for environment 3 jobs is artificial here for my cut-off. The other jobs all have their data end in time when the jobs completed on their own.
One last point I want to make is that the jobs may not necessarily have landed on the same type (speed) of nodes (I did not require this), so one should not draw conclusions from the time duration that a job ran in one environment versus another.
Some observations:
- There seem to be two different classes of jobs in this set: those that use about 1300-1400 MiB for the bulk of the job, and those that are up around 1700-1800 MiB. I'm not sure there's anything to make of this, but it would be interesting if jobs are able to be classified before running them if memory becomes a critical factor.
- The difference in memory used by native SL7 condor jobs vs. SL7 container jobs on SL7 is essentially negligible.
- The difference in memory used by SL7 container jobs on Alma 9 appears to generally be ~50 MiB higher than the same SL7 container jobs on SL7.
»
- genevb's blog
- Login or register to post comments