- genevb's home page
- Posts
- 2025
- 2024
- 2023
- 2022
- September (1)
- 2021
- 2020
- 2019
- December (1)
- October (4)
- September (2)
- August (6)
- July (1)
- June (2)
- May (4)
- April (2)
- March (3)
- February (3)
- 2018
- 2017
- December (1)
- October (3)
- September (1)
- August (1)
- July (2)
- June (2)
- April (2)
- March (2)
- February (1)
- 2016
- November (2)
- September (1)
- August (2)
- July (1)
- June (2)
- May (2)
- April (1)
- March (5)
- February (2)
- January (1)
- 2015
- December (1)
- October (1)
- September (2)
- June (1)
- May (2)
- April (2)
- March (3)
- February (1)
- January (3)
- 2014
- December (2)
- October (2)
- September (2)
- August (3)
- July (2)
- June (2)
- May (2)
- April (9)
- March (2)
- February (2)
- January (1)
- 2013
- December (5)
- October (3)
- September (3)
- August (1)
- July (1)
- May (4)
- April (4)
- March (7)
- February (1)
- January (2)
- 2012
- December (2)
- November (6)
- October (2)
- September (3)
- August (7)
- July (2)
- June (1)
- May (3)
- April (1)
- March (2)
- February (1)
- 2011
- November (1)
- October (1)
- September (4)
- August (2)
- July (4)
- June (3)
- May (4)
- April (9)
- March (5)
- February (6)
- January (3)
- 2010
- December (3)
- November (6)
- October (3)
- September (1)
- August (5)
- July (1)
- June (4)
- May (1)
- April (2)
- March (2)
- February (4)
- January (2)
- 2009
- November (1)
- October (2)
- September (6)
- August (4)
- July (4)
- June (3)
- May (5)
- April (5)
- March (3)
- February (1)
- 2008
- 2005
- October (1)
- My blog
- Post new blog entry
- All blogs
Extracting useful DAQ info on AuAu27 abort gap cleaning events
Updated on Thu, 2018-10-04 01:25. Originally created by genevb on 2018-08-14 16:27.
Contents:
____________
INITIAL FINDINGS: 2018-08-14
(For background details on the SpaceCharge issues, please see SpaceCharge fluctuations in AuAu27)
Jeff Landgraf provided me with files containing potentially useful DAQ information from every event in 4 consecutive AuAu27 runs (19132073-19132076, hereafter referred to as runs 3-6). These files clearly show the 1 Hz pulsing of large events, but contain useless information on lots of other events too (e.g. on the order of 100 MB for each run!). For eventual entry into a database, the information needs to be reduced to cover only those events which are concerned with the abort gap cleaning.
I foresee two ways to reduce the information:
For item 2, one should not just arbitrarily cut on event size. Here are the event size distributions (log-log plot) for the 3 bunch indices of interest (yellow) and the rest (blue):

There seems to be a jump at just about 1 MB for both distributions. Perhaps these are the "ADC" events that get recorded keeping all of the TPC ADC information. A smart script might look for isolated events, as the ADC events would be, to discard them. This is because the abort gap cleaning has a duration that spans several consecutive DAQ events. For now I will ignore that these are there, but I will try to come back and treat them at some point (though I'm even less sure about what to do for those events which overlap the sets: part of an abort gap cleaning and ADC information is kept).
I wrote a macro to run a FFT on the data to measure signal-to-noise as a function of where one cuts on a minimum event size, with the idea that the "signal" in this case is the 1 Hz abort gap cleaning, and the "noise" is randomly distributed frequencies. Here are the results looking at the 4 runs independently. Note, I summed 3 frequency bins (1.0 Hz ±1 frequency bin) to define the signal and noise, as the side bins appear to carry a significant amount of signal as well.
The runs are qualitatively similar, and although run 3's signal seems to fade out more rapidly for large event sizes, the signal-to-noise seems to be reasonably consistent with the other runs. I think these are similar enough that we can go ahead and combine the 4 runs for better statistics.
Next, I do just that, offsetting bunch crossing numbers for the 4 runs to align the abort gaps, to get a more statistically powerful measure of the best place to put the cut. Here is that result (note that I changed the event size axis range to get a clearer look):
My take: there is significant noise for events smaller than 0.2 MB (200 kB). There seems to be a plateau of signal-to-noise above this number. Cutting on the 3 bunch crossing indices AND greater that 0.2 MB results in keeping something like 0.75% of the events.
Miscellaneous:
-Gene
____________
UPDATE 1: 2018-08-16
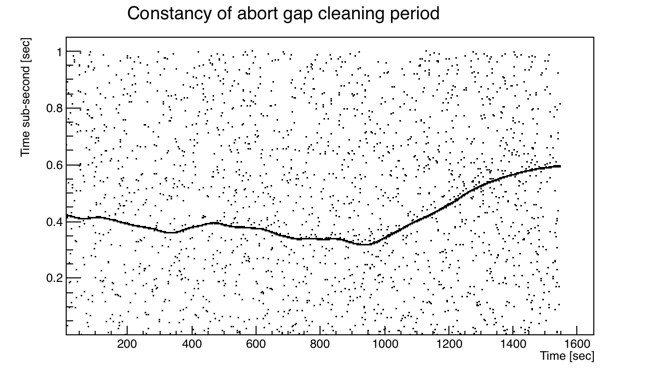
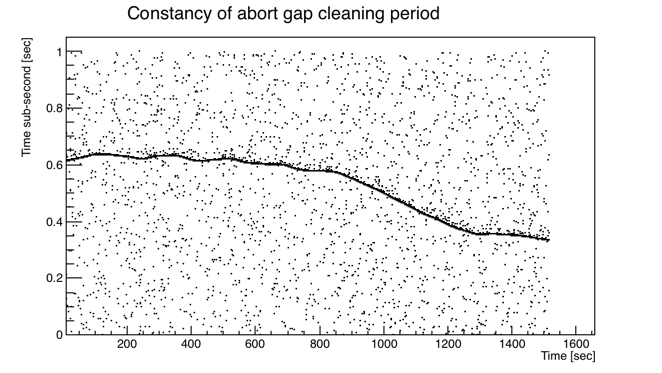
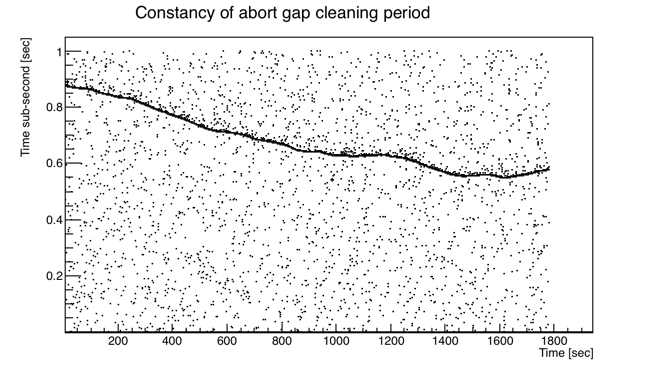
I decided to write a "cluster finder" to try to exclude ADC events, which should only be singles, though they may still possibly occur during an abort gap event. I decided to try to take advantage of the ~1 Hz expectation for arrival of any cluster after finding any given cluster, so I looked to see if I could pre-determine, before cluster-finding, some easy-to-cut selection of when in time to look for clusters. My thought was that all real clusters should arrive at the same "sub-second" if the abort gap cleaning events occurred regularly at 1 Hz, and if it wasn't exactly 1 Hz, this scale factor could be calibrated. What I found instead was that the frequency was neither precisely 1 Hz, nor constant! Here are plots of the sub-second vs. seconds in the run for the candidate abort gap events using cuts of event size > 0.2 MB and bunch index within +/-1 of the identified bad bunch index for the 4 runs (I've shifted the sub-second on some of them to avoid crossing over 0):
The band of abort gap cleaning events is clear and is still selectable by segmenting the data in time and identifying an event-size-weighted sub-second mean, which is quite accurate as long as I keep that mean away from 0 and 1 by applying some kind of overall sub-second shift. So I apply a cut of being within ±20 ms of the weighted mean for any given 30-second window.
After more tuning, I found that I was generally able to get one "cluster" of large events per second while excluding single-hit clusters, and only very rarely within a second (fewer than 1 per 1000 seconds) getting zero clusters or two clusters of more than one large event (between which I could pick the cluster which included more events, which I decided was a better criteria than cluster-integrated data size because the latter might be significantly altered by ADC events). While not perfect, this is probably good enough for our purpose. The cuts involved:

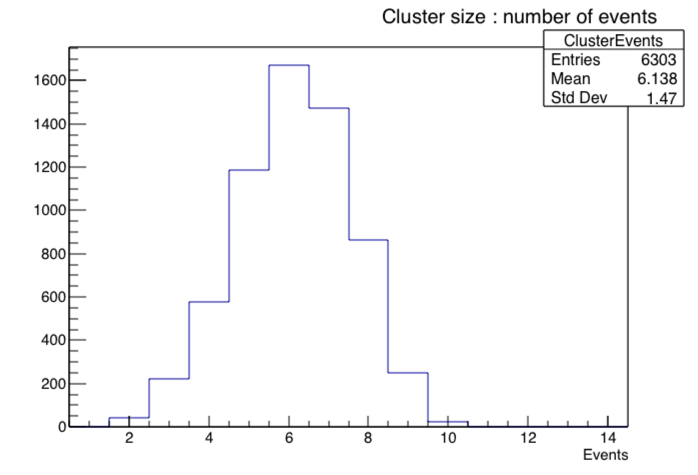

Using method 1 seems to more clearly show that there are two groups of data. The group with larger summed cluster sizes may contain ADC events, yet to be determined. Otherwise things seem to be in generally good shape.
___________________
UPDATE 2: 2018-08-17
I gave another shot at looking for the ADC events and made the following plot of event size vs. the size of the cluster that its in. There appears to be a spurious band of hits above 15 MB that dominate their cluster sizes and seem likely candidates for being the ADC events. So in the right plot, I've color-coded entries for any given cluster by the number of events in that cluster above 15 MB:


By the way, it turns out that the fraction of events (and clusters, actually) that have an ADC candidate is 1 in ~23. That sounds pretty similar to what that number should be (though I don't recall at the moment exactly what it is).
So I decided to play with reducing those events' sizes by some fraction to see if I can make their hit-to-cluster relationships match the clusters with no ADC candidate events. Here are the profile plots for the 0, 1, and 2-candidate-event clusters (same color scheme as above) after reductions to 15%, 10%, and 5% their original size (to be clear, I'm not reducing the entire cluster size, just the size of the events above 15 MB within clusters):



The reduction to 10% original size matches quite well, and I probably don't have statistical power (nor likely the need) to be more precise. Here is what the non-profile (2D) distributions look like using 10% reduction of those hits' sizes, which I think also shows reasonably similar distributions.

Using this reduction, the upper lobe of the cluster size distributions of course disappears, and we are left with the cluster data-event correlation plot looking like this, which to me also looks very reasonable:

A remaining flaw is that ADC events in the cluster which are below 15 MB are not being corrected in this scheme. So there may still be some degree of artificial inflation of the cluster sizes by a few MB in some cases. But given that the mean cluster size is over 20 MB, I'm not going to worry at that level: I'm guessing that we're getting the cluster size correct to within about ±25% and that's probably good enough.
___________________
UPDATE 3: 2018-08-17
Jeff updated the provided DAQ information to include a robust flag on whether an event was an ADC one or not. Using that, I can reduce ADC events in a more straightforward manner. The results are nearly identical to what I was getting with my 15 MB discriminator, so I think it's fair to say that things are in really good shape now for cluster-finding.

___________________
UPDATE 4: 2018-09-21
Looking into some of the missed clusters, I found that some of them had only a single, sizable event (even after ADC corrections), which were very likely to be from the abort gap cleaning. So I allowed single event clusters and found that it of course also introduced some much smaller data-size clusters, forming a second island (the tip of which was visible in the earlier plots) of what are probably standard collisions and not due to the abort gap cleaning. This is made all the more evident in the second plot below, which is the same data, but not discarding the secondary clusters found within the expected time window, which then includes a large number of small-size clusters that are likely standard collisions. In this data, they all have data sizes smaller than 1.25 MB, and 2 or fewer events in the cluster. It would not be difficult to exclude these from the database, but...
...that implies a tuning of the cut which is not general for different colliding species. The cuts I applied to timing between events are, I would guess, specific to abort gap cleaning, but not specific to AuAu27. So I'm a bit concerned about implementing a data size cut at 1.25 MB. And without such a cut, is there any harm? These events are so small (1.5-to-2.0 orders of magnitude down from the bulk of the problem events) that they will convert into minuscule distortion corrections that will almost certainly be invisible in impact. Further, these clusters are in fact real depositions of space charge in the TPC toward the higher end of the spectrum of charge produced by AuAu27 collisions and would in a perfect world benefit from supplementary correction anyhow, though that raises the caveat that such high-charge events are not supplementarily corrected if they aren't from the isolated "bad bunch" indices and in-time with the expected sub-second window for the abort gap cleaning.
Anyhow, my view for now is to leave them in and not worry about them.
I should note that I also fixed a bug from before where I wasn't accounting for ADC event size correction when determining the sub-second expectations, which caused some ADC events to skew some expectations. And lastly I fixed a bug where I picked the wrong cluster candidate when candidates were the same number of events because I hadn't used data size as a tiebreaker (particularly important when accepting single-event clusters).


Further, I should note that the codes I've written for taking the input from DAQ that Jeff L. had provided, and transforming into database tables, are now in CVS under offline/users/genevb/AbortGapClusters :
___________________
UPDATE 5: 2018-10-03
I made a plot of the event cluster size [MB] vs. time [sec] for all 4 runs using the result files from abortGapClusters.C. Here I have introduced an artificial start time for each of the 4 runs I studied, but the time evolution within the runs is correct. It is very interesting to see that the size of the clusters, and therefore the amount of charge deposited in the TPC, was much smaller at the start of the fill (the fill began only a few minutes before 19132073, as there was a single emc-check run about 5 minutes before that one) and then grew, probably reflecting the amount of de-bunched beam increasing over time and then stabilizing. Importantly, the correlation with charge deposited in the TPC has been corroborated by looking at signed DCAs from the beginning of run 19132073 and seeing no sawtooth pattern, while the beginning of run 19132074 clearly shows the sawtooth due to the deposited charge (see You do not have access to view this node).

Perhaps another thing to note is that all the really small clusters I said previously were probably regular AuAu collisions came at the beginning of the fill. I'm not sure whether that implies these are really abort gap cleaning events, or just that the abort gap cleaning events were so small that they're anyhow difficult to distinguish from the large end of the spectrum of AuAu collisions. But it is not important in the end.
-Gene
- INITIAL FINDINGS: 2018-08-14
- UPDATE 1: 2018-08-16
- UPDATE 2: 2018-08-17
- UPDATE 3: 2018-08-17
- UPDATE 4: 2018-09-21
- UPDATE 5: 2018-10-03
____________
INITIAL FINDINGS: 2018-08-14
(For background details on the SpaceCharge issues, please see SpaceCharge fluctuations in AuAu27)
Jeff Landgraf provided me with files containing potentially useful DAQ information from every event in 4 consecutive AuAu27 runs (19132073-19132076, hereafter referred to as runs 3-6). These files clearly show the 1 Hz pulsing of large events, but contain useless information on lots of other events too (e.g. on the order of 100 MB for each run!). For eventual entry into a database, the information needs to be reduced to cover only those events which are concerned with the abort gap cleaning.
I foresee two ways to reduce the information:
- Select on bunch crossing index (between 0 and 119)
- Select on event size
For item 2, one should not just arbitrarily cut on event size. Here are the event size distributions (log-log plot) for the 3 bunch indices of interest (yellow) and the rest (blue):
There seems to be a jump at just about 1 MB for both distributions. Perhaps these are the "ADC" events that get recorded keeping all of the TPC ADC information. A smart script might look for isolated events, as the ADC events would be, to discard them. This is because the abort gap cleaning has a duration that spans several consecutive DAQ events. For now I will ignore that these are there, but I will try to come back and treat them at some point (though I'm even less sure about what to do for those events which overlap the sets: part of an abort gap cleaning and ADC information is kept).
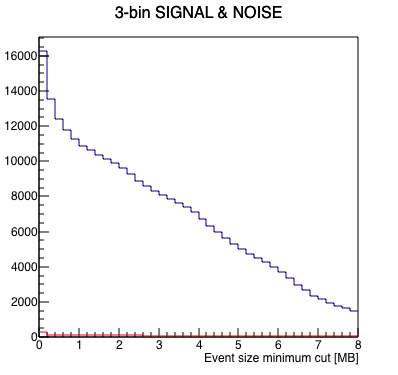
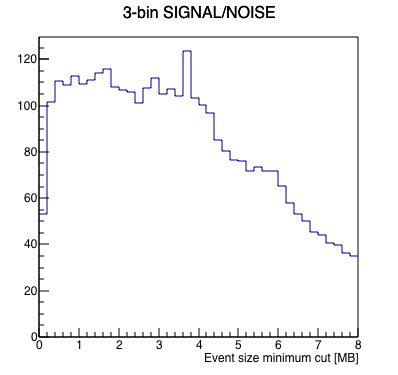
I wrote a macro to run a FFT on the data to measure signal-to-noise as a function of where one cuts on a minimum event size, with the idea that the "signal" in this case is the 1 Hz abort gap cleaning, and the "noise" is randomly distributed frequencies. Here are the results looking at the 4 runs independently. Note, I summed 3 frequency bins (1.0 Hz ±1 frequency bin) to define the signal and noise, as the side bins appear to carry a significant amount of signal as well.
| Run | Results | Signal (blue) & Noise (red) | Signal/Noise |
|---|---|---|---|
| 3 | 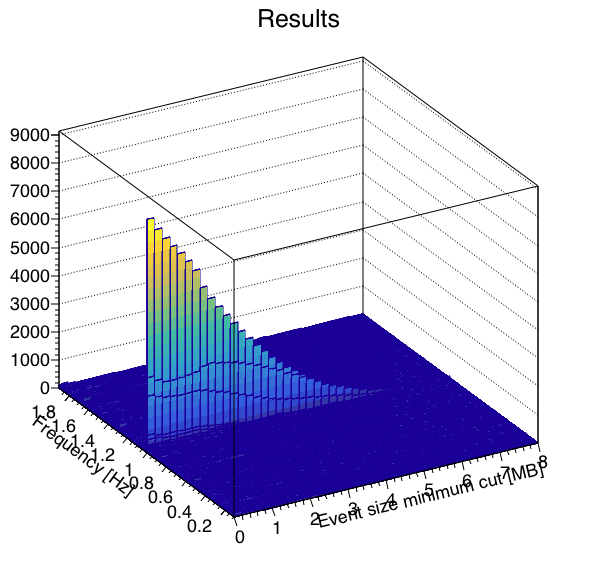 |
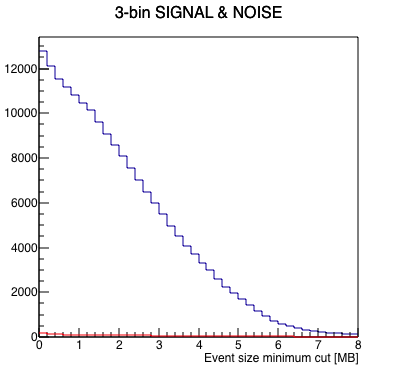 |
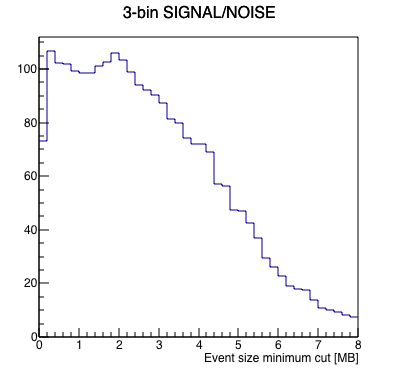 |
| 4 | 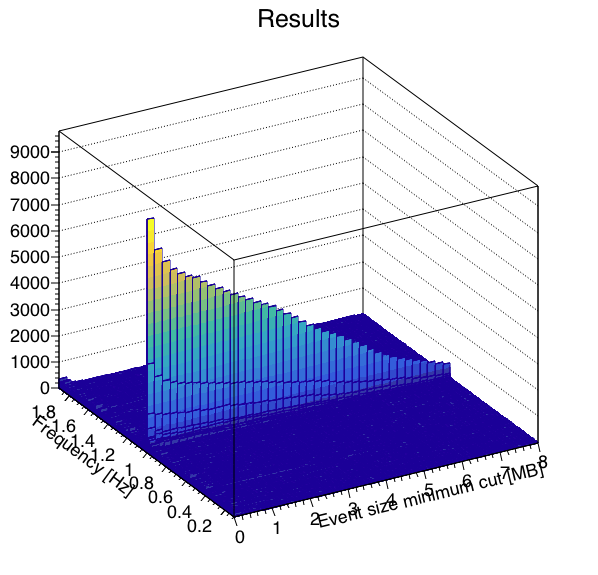 |
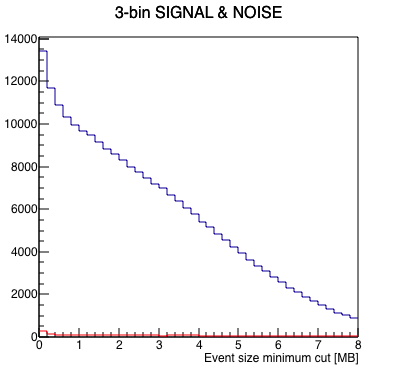 |
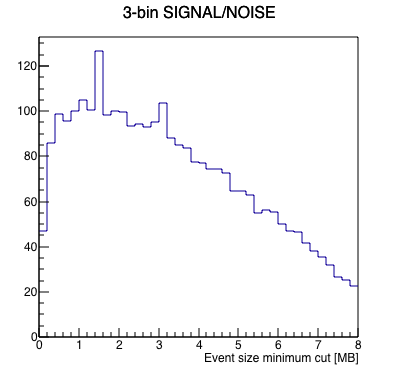 |
| 5 | 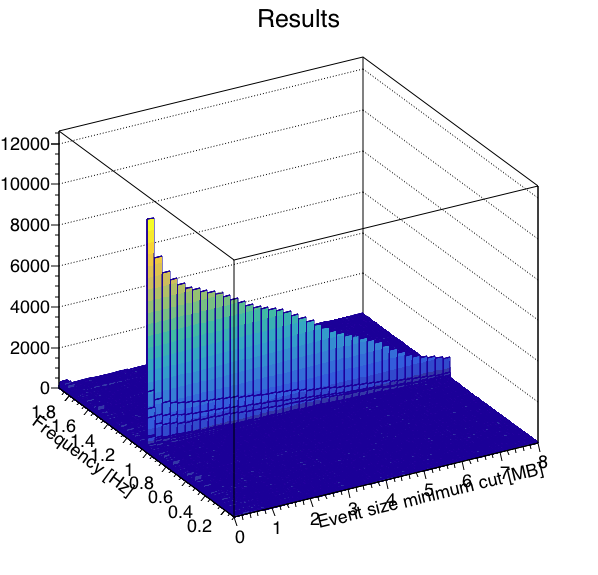 |
 |
 |
| 6 | 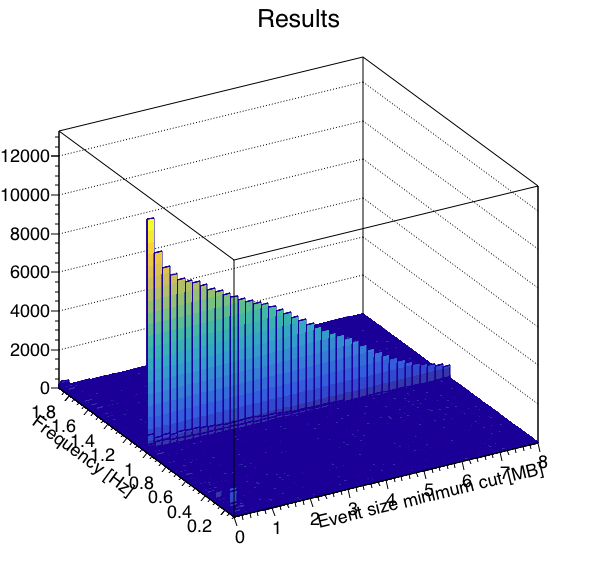 |
 |
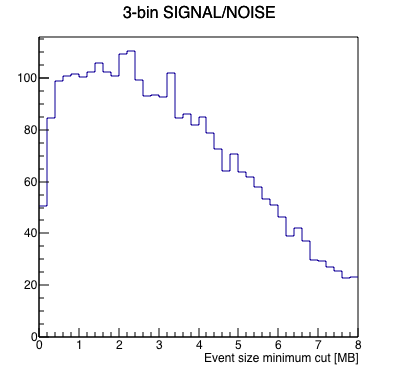 |
The runs are qualitatively similar, and although run 3's signal seems to fade out more rapidly for large event sizes, the signal-to-noise seems to be reasonably consistent with the other runs. I think these are similar enough that we can go ahead and combine the 4 runs for better statistics.
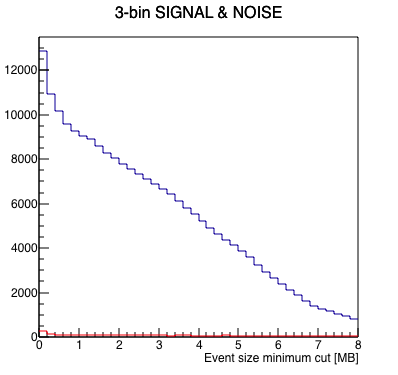
Next, I do just that, offsetting bunch crossing numbers for the 4 runs to align the abort gaps, to get a more statistically powerful measure of the best place to put the cut. Here is that result (note that I changed the event size axis range to get a clearer look):
| Results | Signal (blue) & Noise (red) | Signal/Noise |
|---|---|---|
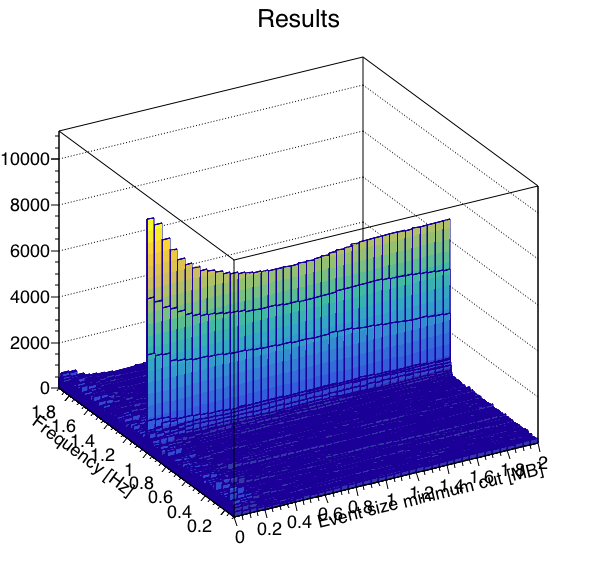 |
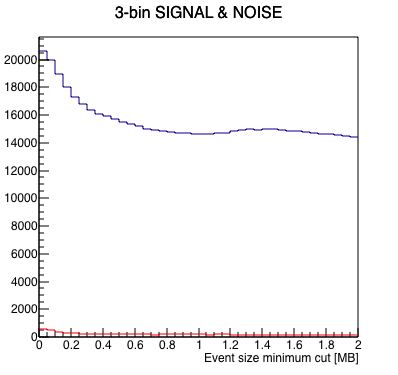 |
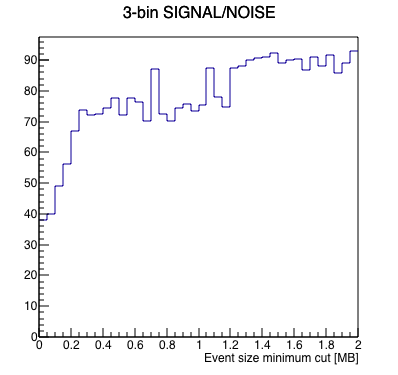 |
My take: there is significant noise for events smaller than 0.2 MB (200 kB). There seems to be a plateau of signal-to-noise above this number. Cutting on the 3 bunch crossing indices AND greater that 0.2 MB results in keeping something like 0.75% of the events.
Miscellaneous:
- Using 10 Mhz as a rough order-of-magnitude estimate for the RHIC clock, it only takes a little over 7 minutes to exceed 232 bunch crossings. So one must make the database table field for the bunch crossing number capable of at least 35-36 unsigned bits to cover runs of duration that could exceed half an hour. A 64-bit integer (long int; doesn't matter if it's signed or not) would be way more than enough.
-Gene
____________
UPDATE 1: 2018-08-16
I decided to write a "cluster finder" to try to exclude ADC events, which should only be singles, though they may still possibly occur during an abort gap event. I decided to try to take advantage of the ~1 Hz expectation for arrival of any cluster after finding any given cluster, so I looked to see if I could pre-determine, before cluster-finding, some easy-to-cut selection of when in time to look for clusters. My thought was that all real clusters should arrive at the same "sub-second" if the abort gap cleaning events occurred regularly at 1 Hz, and if it wasn't exactly 1 Hz, this scale factor could be calibrated. What I found instead was that the frequency was neither precisely 1 Hz, nor constant! Here are plots of the sub-second vs. seconds in the run for the candidate abort gap events using cuts of event size > 0.2 MB and bunch index within +/-1 of the identified bad bunch index for the 4 runs (I've shifted the sub-second on some of them to avoid crossing over 0):
| run 3 | run 4 | run 5 | run 6 |
|---|---|---|---|
 |
 |
 |
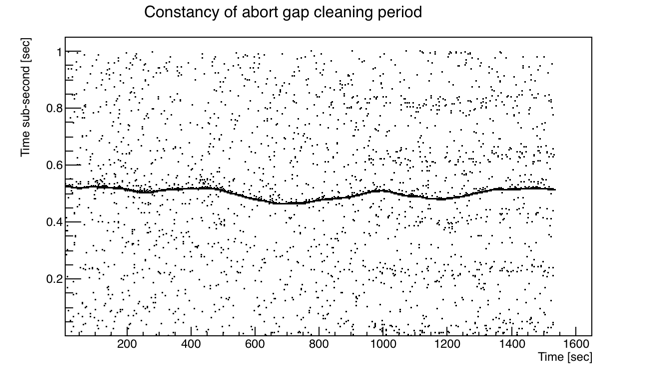 |
The band of abort gap cleaning events is clear and is still selectable by segmenting the data in time and identifying an event-size-weighted sub-second mean, which is quite accurate as long as I keep that mean away from 0 and 1 by applying some kind of overall sub-second shift. So I apply a cut of being within ±20 ms of the weighted mean for any given 30-second window.
After more tuning, I found that I was generally able to get one "cluster" of large events per second while excluding single-hit clusters, and only very rarely within a second (fewer than 1 per 1000 seconds) getting zero clusters or two clusters of more than one large event (between which I could pick the cluster which included more events, which I decided was a better criteria than cluster-integrated data size because the latter might be significantly altered by ADC events). While not perfect, this is probably good enough for our purpose. The cuts involved:
- Hits used in cluster-finding are bigger than 0.3 MB (as opposed to the 0.2 MB I had earlier thought would suffice).
- Cluster starts within 20 ms of 30-second window weighted mean expectation of sub-second.
- Cluster spans less than 4 ms in duration.
- Hits within a cluster have no time gaps larger than 1.2 ms.
- Simply sum the size of the data from each event of the cluster: sum(MB/event)
- Integrate the size of the data over time, assuming straight-line iterpolation between data points: sum(Δt * MB/event)
Using method 1 seems to more clearly show that there are two groups of data. The group with larger summed cluster sizes may contain ADC events, yet to be determined. Otherwise things seem to be in generally good shape.
___________________
UPDATE 2: 2018-08-17
I gave another shot at looking for the ADC events and made the following plot of event size vs. the size of the cluster that its in. There appears to be a spurious band of hits above 15 MB that dominate their cluster sizes and seem likely candidates for being the ADC events. So in the right plot, I've color-coded entries for any given cluster by the number of events in that cluster above 15 MB:
By the way, it turns out that the fraction of events (and clusters, actually) that have an ADC candidate is 1 in ~23. That sounds pretty similar to what that number should be (though I don't recall at the moment exactly what it is).
So I decided to play with reducing those events' sizes by some fraction to see if I can make their hit-to-cluster relationships match the clusters with no ADC candidate events. Here are the profile plots for the 0, 1, and 2-candidate-event clusters (same color scheme as above) after reductions to 15%, 10%, and 5% their original size (to be clear, I'm not reducing the entire cluster size, just the size of the events above 15 MB within clusters):
The reduction to 10% original size matches quite well, and I probably don't have statistical power (nor likely the need) to be more precise. Here is what the non-profile (2D) distributions look like using 10% reduction of those hits' sizes, which I think also shows reasonably similar distributions.
Using this reduction, the upper lobe of the cluster size distributions of course disappears, and we are left with the cluster data-event correlation plot looking like this, which to me also looks very reasonable:
A remaining flaw is that ADC events in the cluster which are below 15 MB are not being corrected in this scheme. So there may still be some degree of artificial inflation of the cluster sizes by a few MB in some cases. But given that the mean cluster size is over 20 MB, I'm not going to worry at that level: I'm guessing that we're getting the cluster size correct to within about ±25% and that's probably good enough.
___________________
UPDATE 3: 2018-08-17
Jeff updated the provided DAQ information to include a robust flag on whether an event was an ADC one or not. Using that, I can reduce ADC events in a more straightforward manner. The results are nearly identical to what I was getting with my 15 MB discriminator, so I think it's fair to say that things are in really good shape now for cluster-finding.
___________________
UPDATE 4: 2018-09-21
Looking into some of the missed clusters, I found that some of them had only a single, sizable event (even after ADC corrections), which were very likely to be from the abort gap cleaning. So I allowed single event clusters and found that it of course also introduced some much smaller data-size clusters, forming a second island (the tip of which was visible in the earlier plots) of what are probably standard collisions and not due to the abort gap cleaning. This is made all the more evident in the second plot below, which is the same data, but not discarding the secondary clusters found within the expected time window, which then includes a large number of small-size clusters that are likely standard collisions. In this data, they all have data sizes smaller than 1.25 MB, and 2 or fewer events in the cluster. It would not be difficult to exclude these from the database, but...
...that implies a tuning of the cut which is not general for different colliding species. The cuts I applied to timing between events are, I would guess, specific to abort gap cleaning, but not specific to AuAu27. So I'm a bit concerned about implementing a data size cut at 1.25 MB. And without such a cut, is there any harm? These events are so small (1.5-to-2.0 orders of magnitude down from the bulk of the problem events) that they will convert into minuscule distortion corrections that will almost certainly be invisible in impact. Further, these clusters are in fact real depositions of space charge in the TPC toward the higher end of the spectrum of charge produced by AuAu27 collisions and would in a perfect world benefit from supplementary correction anyhow, though that raises the caveat that such high-charge events are not supplementarily corrected if they aren't from the isolated "bad bunch" indices and in-time with the expected sub-second window for the abort gap cleaning.
Anyhow, my view for now is to leave them in and not worry about them.
I should note that I also fixed a bug from before where I wasn't accounting for ADC event size correction when determining the sub-second expectations, which caused some ADC events to skew some expectations. And lastly I fixed a bug where I picked the wrong cluster candidate when candidates were the same number of events because I hadn't used data size as a tiebreaker (particularly important when accepting single-event clusters).
Further, I should note that the codes I've written for taking the input from DAQ that Jeff L. had provided, and transforming into database tables, are now in CVS under offline/users/genevb/AbortGapClusters :
- prepDAQdata.csh : reduce the DAQ data to what is needed for cluster-finding
- abortGapClusters.C : cluster-finding
- makeChargeEventCINT.csh : convert cluster data into CINT files for database upload
___________________
UPDATE 5: 2018-10-03
I made a plot of the event cluster size [MB] vs. time [sec] for all 4 runs using the result files from abortGapClusters.C. Here I have introduced an artificial start time for each of the 4 runs I studied, but the time evolution within the runs is correct. It is very interesting to see that the size of the clusters, and therefore the amount of charge deposited in the TPC, was much smaller at the start of the fill (the fill began only a few minutes before 19132073, as there was a single emc-check run about 5 minutes before that one) and then grew, probably reflecting the amount of de-bunched beam increasing over time and then stabilizing. Importantly, the correlation with charge deposited in the TPC has been corroborated by looking at signed DCAs from the beginning of run 19132073 and seeing no sawtooth pattern, while the beginning of run 19132074 clearly shows the sawtooth due to the deposited charge (see You do not have access to view this node).
Perhaps another thing to note is that all the really small clusters I said previously were probably regular AuAu collisions came at the beginning of the fill. I'm not sure whether that implies these are really abort gap cleaning events, or just that the abort gap cleaning events were so small that they're anyhow difficult to distinguish from the large end of the spectrum of AuAu collisions. But it is not important in the end.
-Gene
»
- genevb's blog
- Login or register to post comments