- genevb's home page
- Posts
- 2025
- 2024
- 2023
- 2022
- September (1)
- 2021
- 2020
- 2019
- December (1)
- October (4)
- September (2)
- August (6)
- July (1)
- June (2)
- May (4)
- April (2)
- March (3)
- February (3)
- 2018
- 2017
- December (1)
- October (3)
- September (1)
- August (1)
- July (2)
- June (2)
- April (2)
- March (2)
- February (1)
- 2016
- November (2)
- September (1)
- August (2)
- July (1)
- June (2)
- May (2)
- April (1)
- March (5)
- February (2)
- January (1)
- 2015
- December (1)
- October (1)
- September (2)
- June (1)
- May (2)
- April (2)
- March (3)
- February (1)
- January (3)
- 2014
- December (2)
- October (2)
- September (2)
- August (3)
- July (2)
- June (2)
- May (2)
- April (9)
- March (2)
- February (2)
- January (1)
- 2013
- December (5)
- October (3)
- September (3)
- August (1)
- July (1)
- May (4)
- April (4)
- March (7)
- February (1)
- January (2)
- 2012
- December (2)
- November (6)
- October (2)
- September (3)
- August (7)
- July (2)
- June (1)
- May (3)
- April (1)
- March (2)
- February (1)
- 2011
- November (1)
- October (1)
- September (4)
- August (2)
- July (4)
- June (3)
- May (4)
- April (9)
- March (5)
- February (6)
- January (3)
- 2010
- December (3)
- November (6)
- October (3)
- September (1)
- August (5)
- July (1)
- June (4)
- May (1)
- April (2)
- March (2)
- February (4)
- January (2)
- 2009
- November (1)
- October (2)
- September (6)
- August (4)
- July (4)
- June (3)
- May (5)
- April (5)
- March (3)
- February (1)
- 2008
- 2005
- October (1)
- My blog
- Post new blog entry
- All blogs
Sti comparison between tags SL16b and StiCA_2016
Updated on Tue, 2016-03-08 15:25. Originally created by genevb on 2016-03-04 16:50.
I processed two different sets of data for track-by-track comparison purposes:
Reconstruction chain: pp2013a,btof,VFPPVnoCTB,beamline,BEmcChkStat,CorrX,OSpaceZ2,OGridLeak3D,SCScalerCal,goptSCE100051,-hitfilt
Correlations and ratios of reconstruction time per event: unoptimized EVAL is a little slower, while optimized EVAL is notably faster.
(Note 1: all 4 chains run at the same time, on the same node, using the same local disk)
(Note 2: first event is the slow outlier as it includes initialization overheads)


Number of "good tracks" used for my comparisons: EVAL optimized has more than SL16b, and unoptimized has fewer.
Track-by-track matching: optimized EVAL seems to introduce the most mis-matches.
SL16b vs. EVAL:
EVAL optimized vs. not:
SL16b optimized vs. EVAL optimized:
Observations are very similar to what was seen in Run 13 pp510.
Reconstruction chain: P2014a,btof,BEmcChkStat,CorrX,OSpaceZ2,OGridLeak3D,SCScalerCal,goptSCE100051,-hitfilt
Correlations and ratios of reconstruction time per event: unoptimized EVAL is a little slower.
(Note 1: both chains run at the same time, on the same node, using the same local disk)
(Note 2: first event is the red marker; it includes initialization overheads)

Number of "good tracks" used for my comparisons: EVAL unoptimized has fewer than SL16b unoptimized, just like with Run 13 pp510.
Track-by-track matching: similar to the Run 13 pp510 results.
SL16b vs. EVAL:
-Gene
- Run 13 pp510: 500 events from st_physics_14079008_raw_1920004.daq
- Run 14 AuAu200: 500 events from st_physics_15164004_raw_2000022.daq
- SL16b
- SL16b optimized
- EVAL
- EVAL optimized
- For pp510, I used all 4 libraries somewhat successfully.
- EVAL optimized introduced "nan" values in one of my comparions quantities, which I ignored for this study: error on the DCA, which is an argument value returned by the function THelixTrack::Dca(), as defined in $STAR/StRoot/StarRoot/THelixTrack.*
- For AuAu200, I used only the non-optimized libraries. This I did because the EVAL optimized jobs aborted quickly, reporting the following:
root4star: .sl64_gcc482/obj/StRoot/StarRoot/THelixTrack.cxx:802: double THelixTrack::Step(const double*, double*, double*) const: Assertion `iter' failed. *** Problem in THElixTrack::Step(vtx) *** double vtx[3]={-nan,-nan,-nan};Clearly there is an issue with the THelixTrack class in optimized EVAL. - SL16b optimized and unoptimized gave identical results within the precision that I used for my comparison values. I believe if one uses higher precision, we've seen occasional differences in the least significant digits due to rounding. Thus, I will show no plots comparing SL16b (unoptimized) to SL16b optimized.
- Cuts to match tracks (by proximity) were the defaults:
- Δ(q/pT) < 0.1 [GeV/c]-1
- Δ(η) < 0.1
- Δ(φ) < 0.15 [rad]
- Cuts to select "good tracks" for use in matching were the defaults:
- Nhits ≥ 25
- Either a BEMC or BTOF match
- 3D DCA < 4 cm to a primary vertex with...
- rank ≥ 0 (pp510) or rank ≥ -5 (AuAu200)
- daughter multiplicity ≥ 5
- daughters matched to BEMC ≥= 1
- |zTPC - zVPD| < 5 cm
Run 13 pp510 comparisons:
Reconstruction chain: pp2013a,btof,VFPPVnoCTB,beamline,BEmcChkStat,CorrX,OSpaceZ2,OGridLeak3D,SCScalerCal,goptSCE100051,-hitfilt
Correlations and ratios of reconstruction time per event: unoptimized EVAL is a little slower, while optimized EVAL is notably faster.
(Note 1: all 4 chains run at the same time, on the same node, using the same local disk)
(Note 2: first event is the slow outlier as it includes initialization overheads)
Number of "good tracks" used for my comparisons: EVAL optimized has more than SL16b, and unoptimized has fewer.
| SL16b | 131612 |
| SL16b optimized | 131612 |
| EVAL | 131201 |
| EVAL optimized | 131887 |
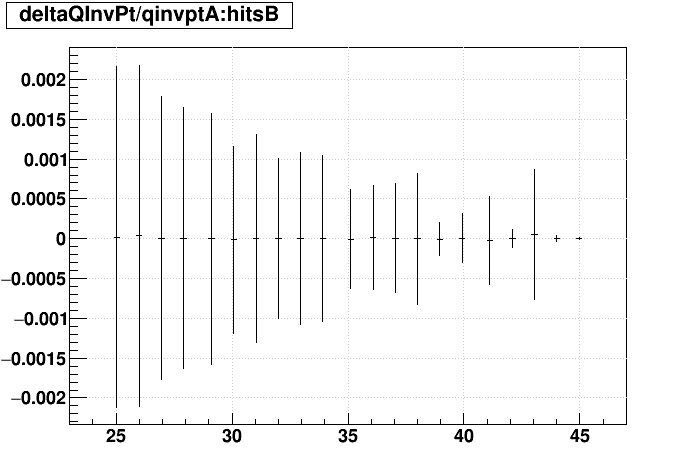
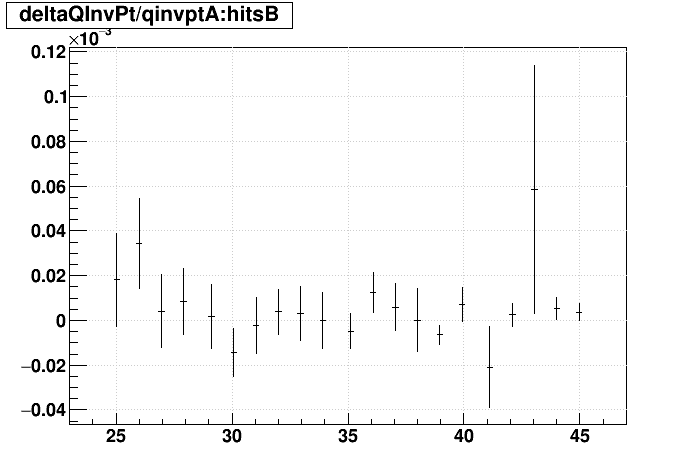
Track-by-track matching: optimized EVAL seems to introduce the most mis-matches.
| A vs. B | matched | unmatched A | unmatched B |
|---|---|---|---|
| SL16b vs. EVAL | 131120 | 492 | 81 |
| SL16b optimized vs. not | 131612 | 0 | 0 |
| EVAL optimized vs. not | 130105 | 1782 | 1096 |
| SL16b optimized vs. EVAL optimized | 130083 | 1529 | 1804 |
SL16b vs. EVAL:
| "zcol" | "profs" | "prof" | |
|---|---|---|---|
| Δ(q/pT)/(q/pT) vs. Nhits | 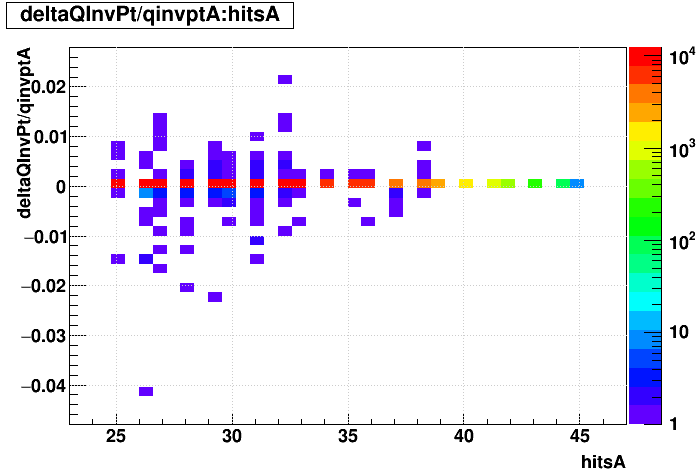 |
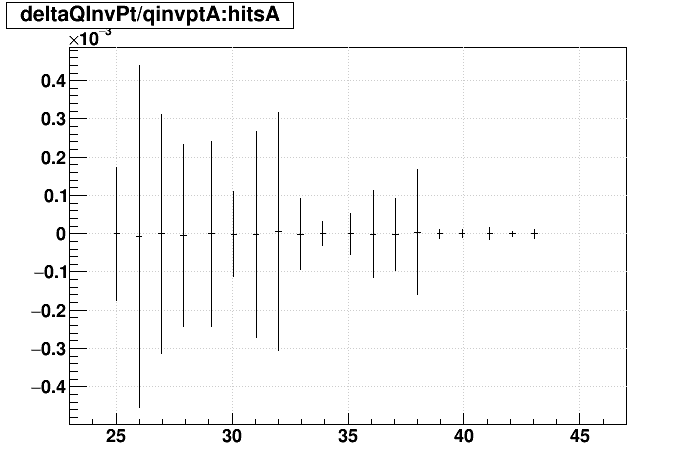 |
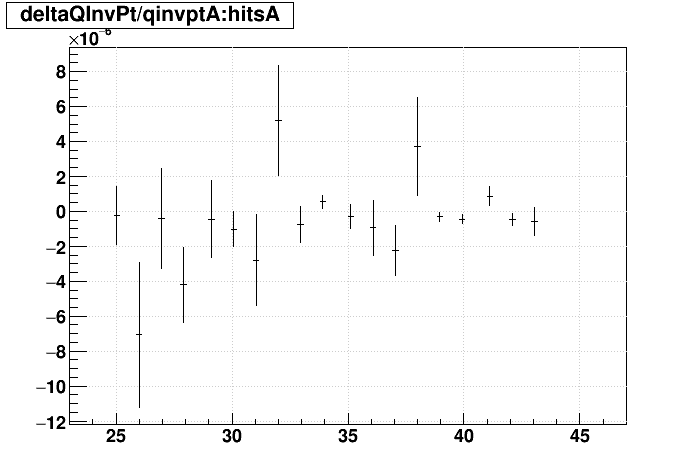 |
| Δ(sDCA) vs. Nhits | 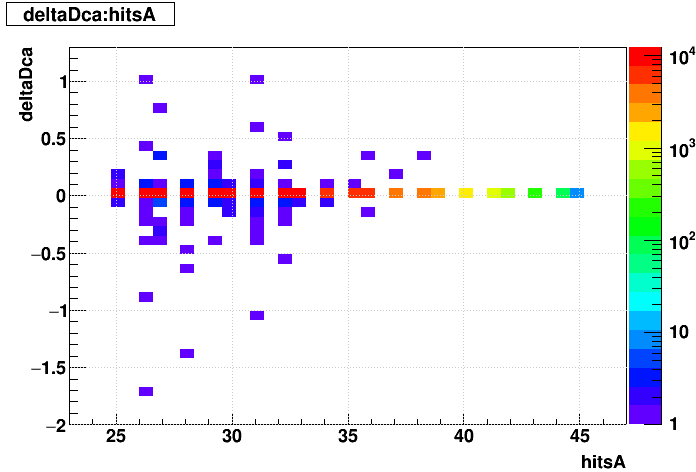 |
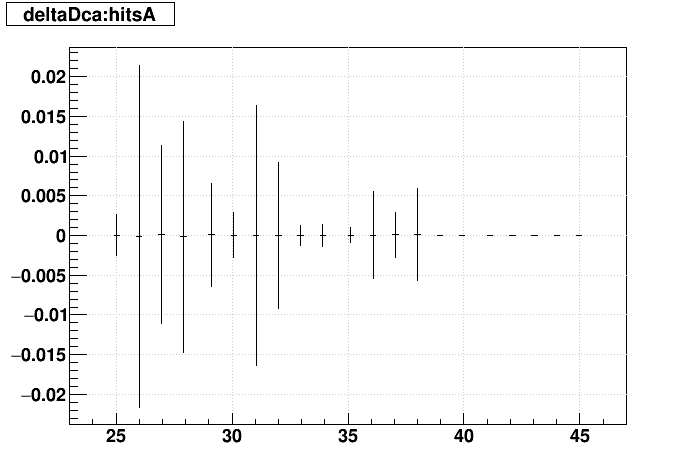 |
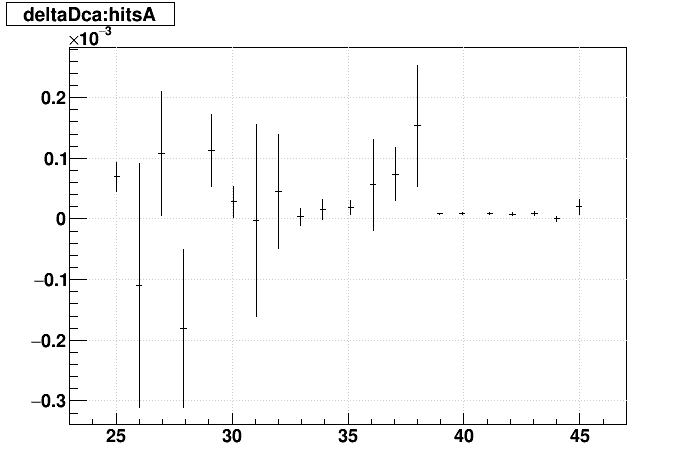 |
| Δ(Nhits) vs. Nhits | 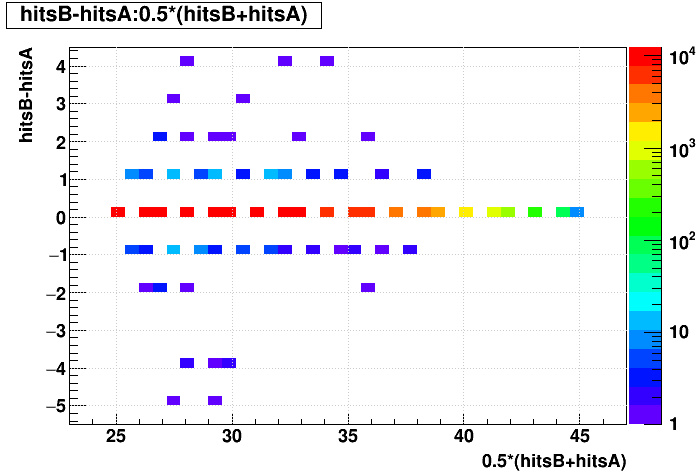 |
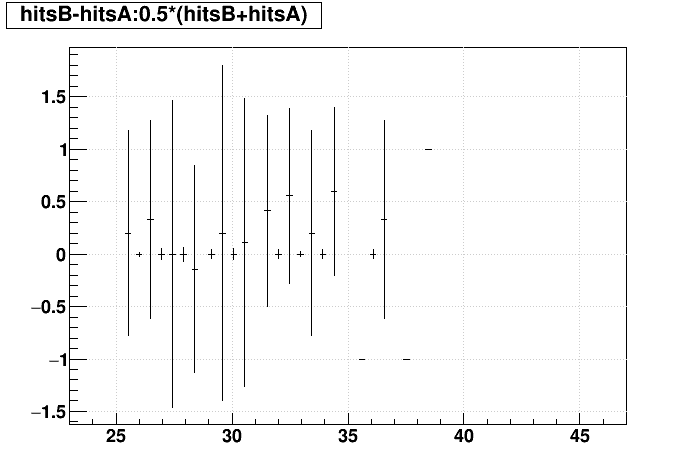 |
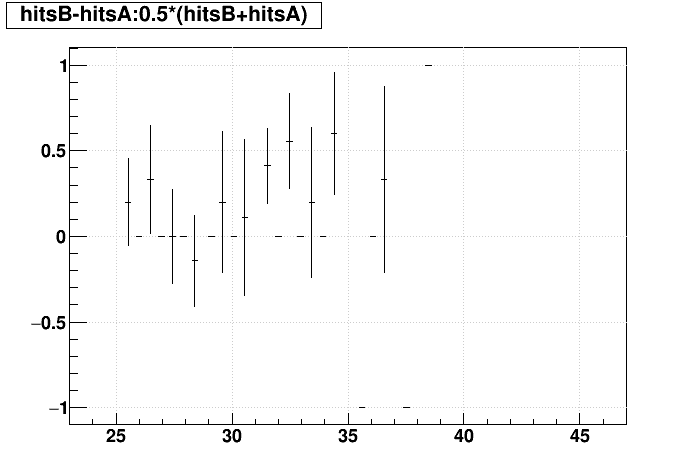 |
EVAL optimized vs. not:
| "zcol" | "profs" | "prof" | |
|---|---|---|---|
| Δ(q/pT)/(q/pT) vs. Nhits | 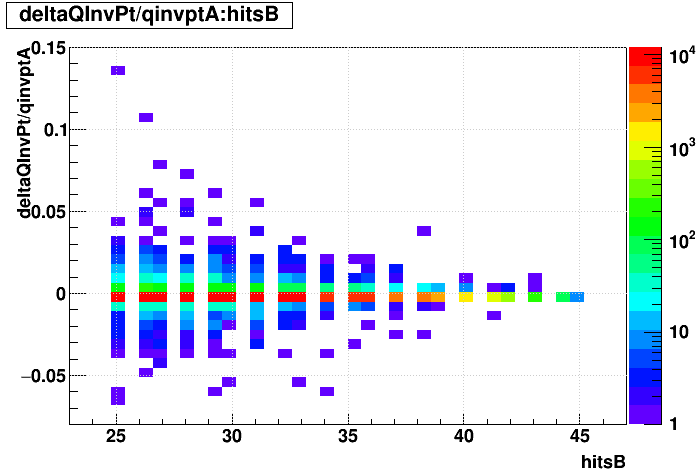 |
 |
 |
| Δ(sDCA) vs. Nhits | 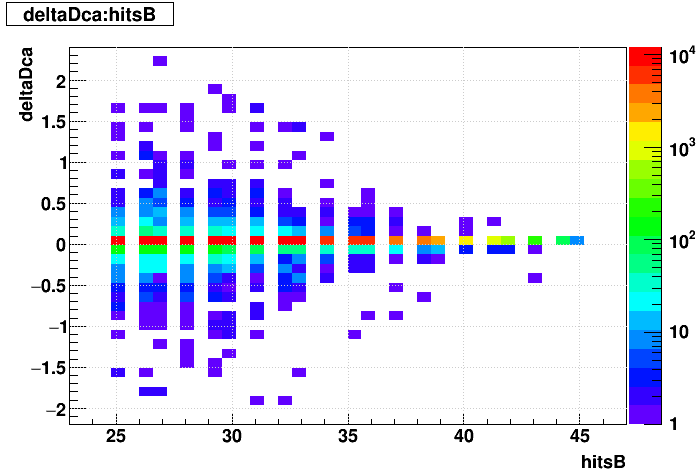 |
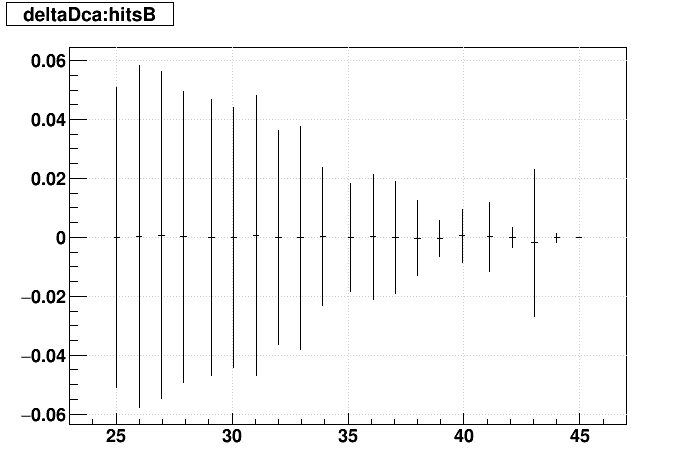 |
 |
SL16b optimized vs. EVAL optimized:
| "zcol" | "profs" | "prof" | |
|---|---|---|---|
| Δ(q/pT)/(q/pT) vs. Nhits | 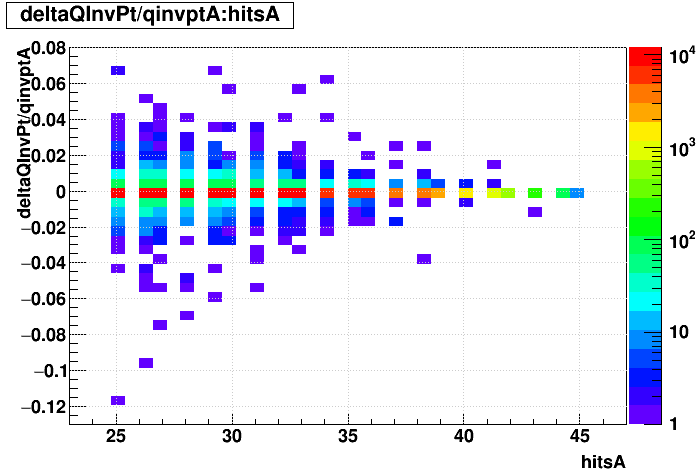 |
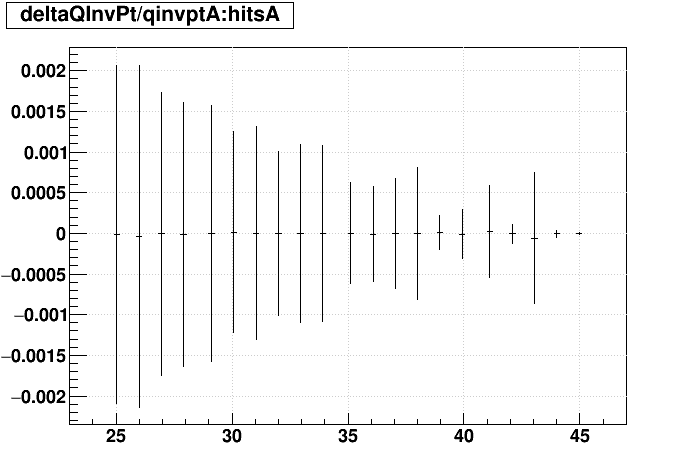 |
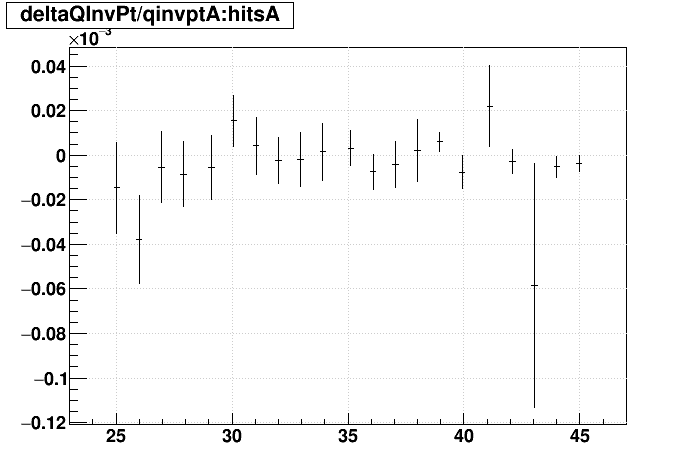 |
| Δ(sDCA) vs. Nhits | 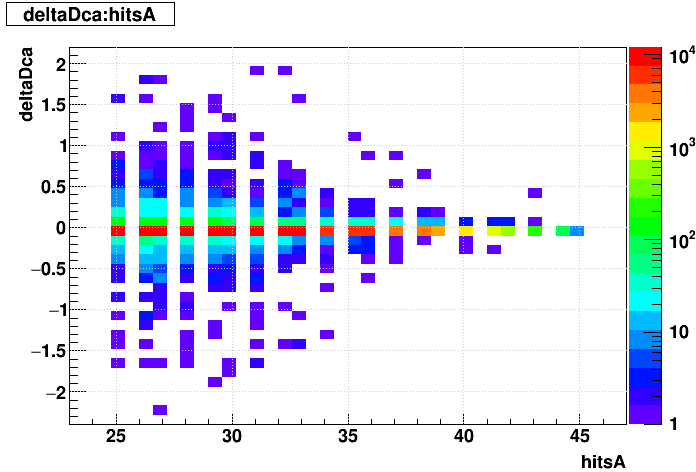 |
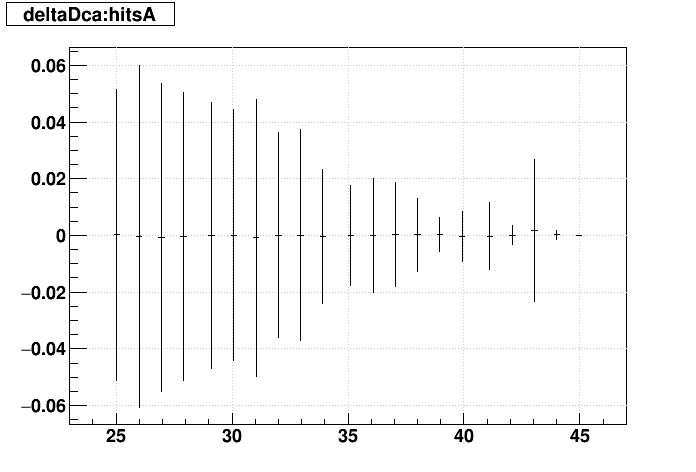 |
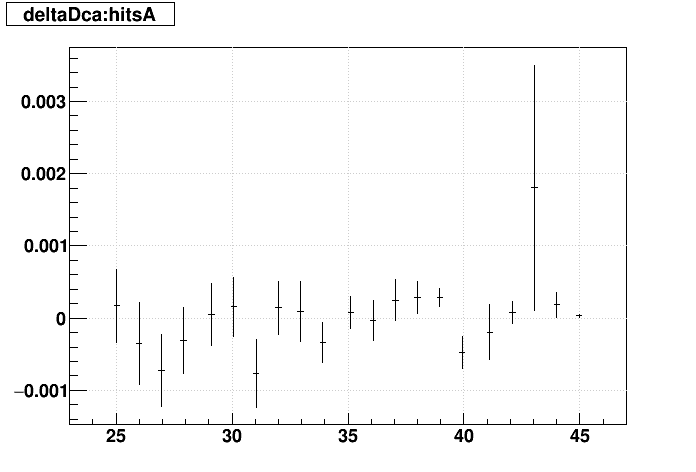 |
| Δ(Nhits) vs. Nhits | 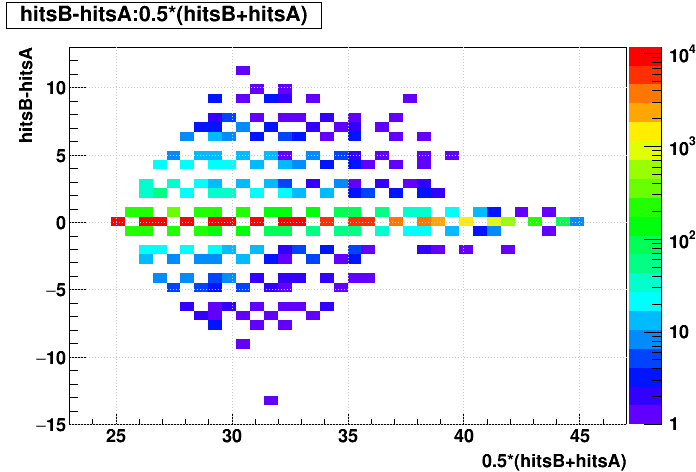 |
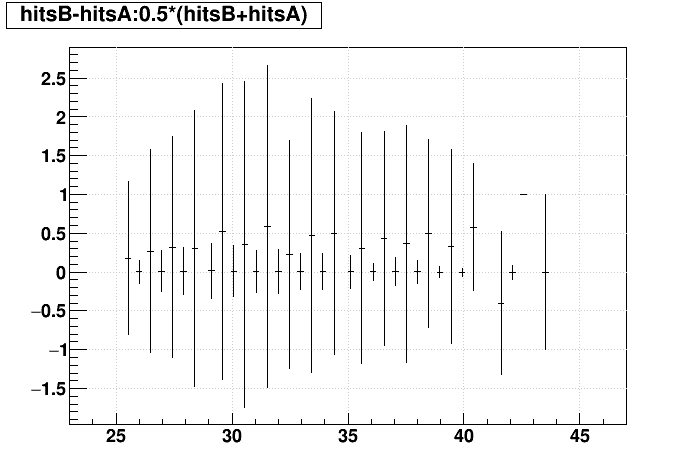 |
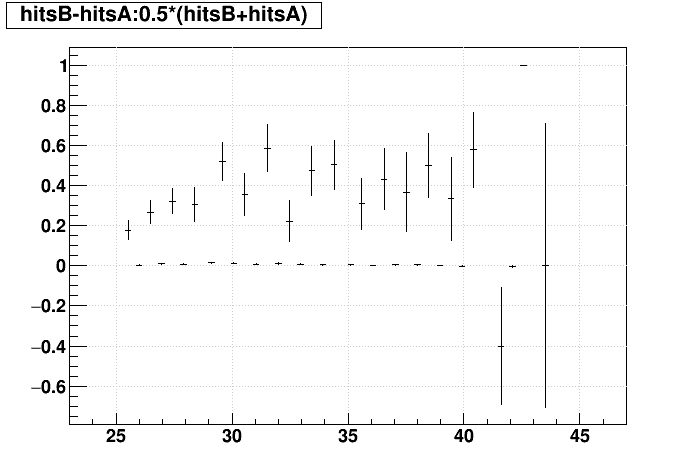 |
Run 14 AuAu200 comparisons:
Observations are very similar to what was seen in Run 13 pp510.
Reconstruction chain: P2014a,btof,BEmcChkStat,CorrX,OSpaceZ2,OGridLeak3D,SCScalerCal,goptSCE100051,-hitfilt
Correlations and ratios of reconstruction time per event: unoptimized EVAL is a little slower.
(Note 1: both chains run at the same time, on the same node, using the same local disk)
(Note 2: first event is the red marker; it includes initialization overheads)
Number of "good tracks" used for my comparisons: EVAL unoptimized has fewer than SL16b unoptimized, just like with Run 13 pp510.
| SL16b | 176359 |
| EVAL | 175727 |
Track-by-track matching: similar to the Run 13 pp510 results.
| A vs. B | matched | unmatched A | unmatched B |
|---|---|---|---|
| SL16b vs. EVAL | 175655 | 704 | 72 |
SL16b vs. EVAL:
| "zcol" | "profs" | "prof" | |
|---|---|---|---|
| Δ(q/pT)/(q/pT) vs. Nhits | 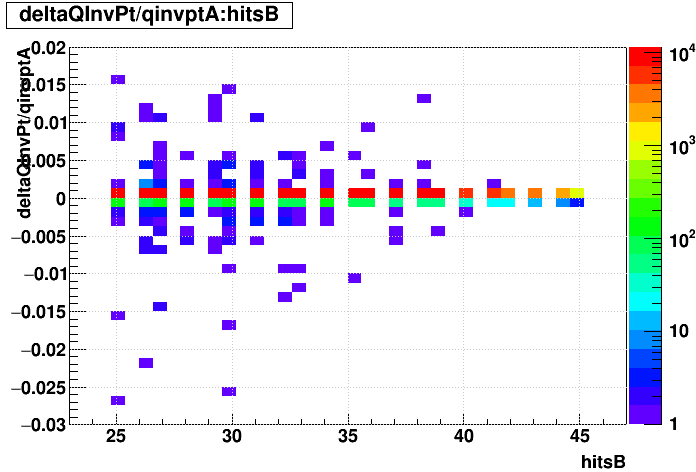 |
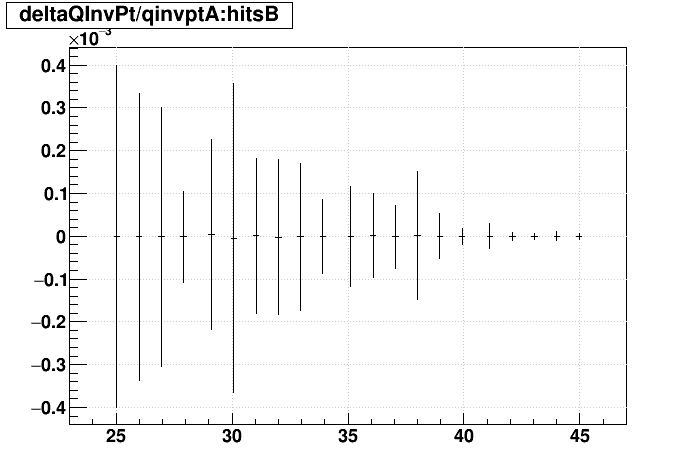 |
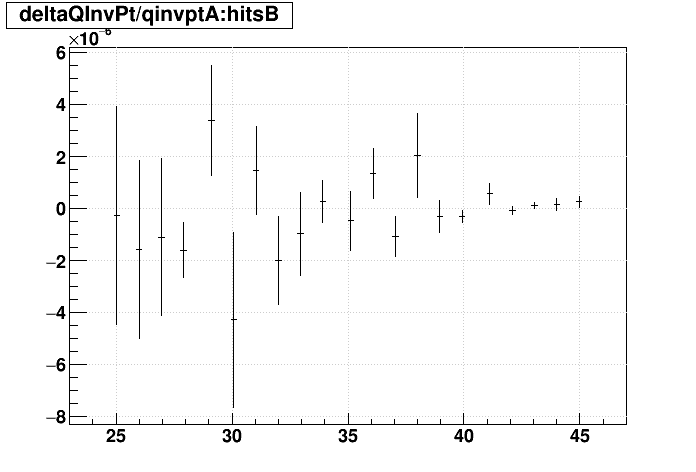 |
| Δ(sDCA) vs. Nhits | 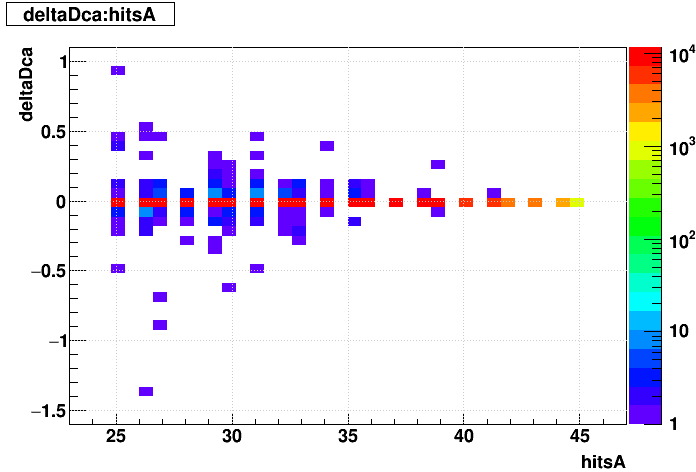 |
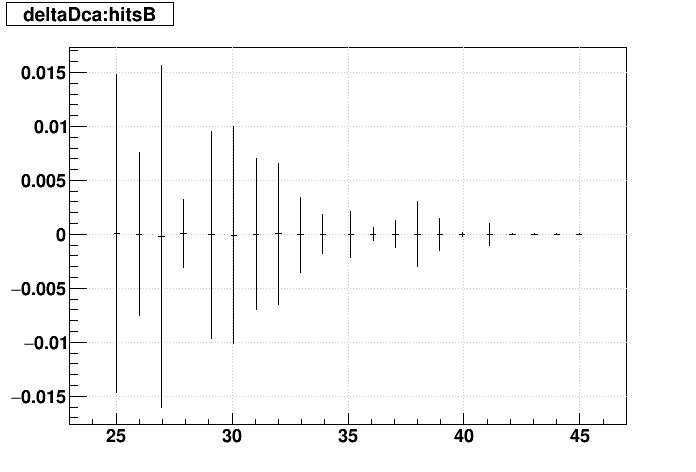 |
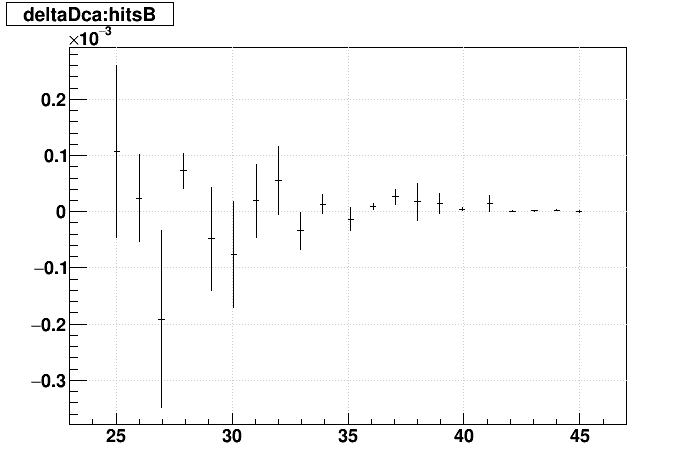 |
| Δ(Nhits) vs. Nhits | 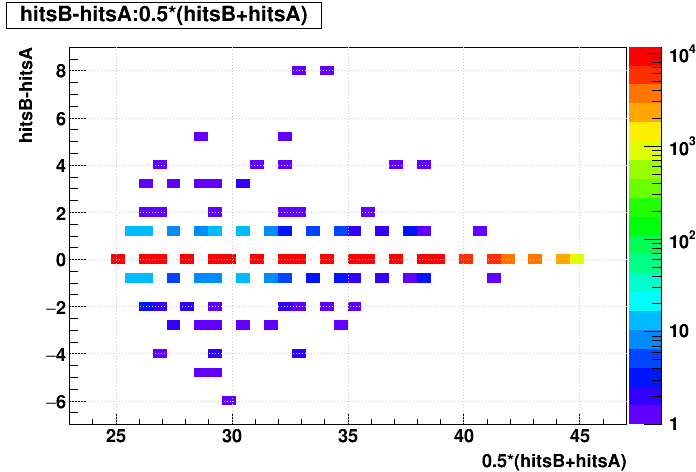 |
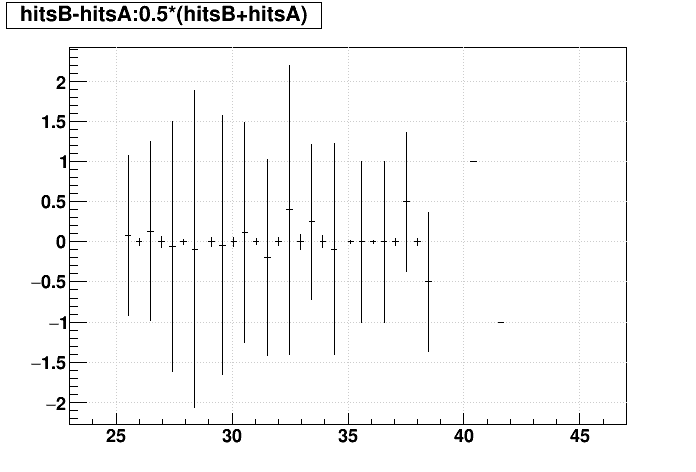 |
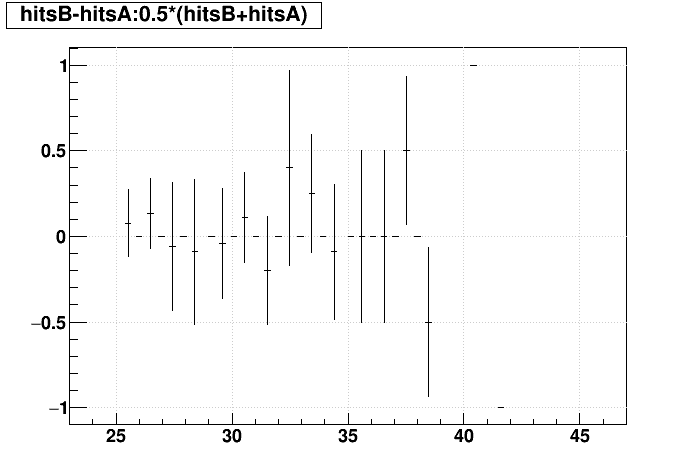 |
-Gene
»
- genevb's blog
- Login or register to post comments