- jeromel's home page
- Posts
- 2025
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- December (1)
- November (1)
- October (2)
- September (1)
- July (2)
- June (1)
- March (3)
- February (1)
- January (1)
- 2014
- 2013
- 2012
- 2011
- 2010
- December (2)
- November (1)
- October (4)
- August (3)
- July (3)
- June (2)
- May (1)
- April (4)
- March (1)
- February (1)
- January (2)
- 2009
- December (3)
- October (1)
- September (1)
- July (1)
- June (1)
- April (1)
- March (4)
- February (6)
- January (1)
- 2008
- My blog
- Post new blog entry
- All blogs
Generic queue between Atlas/STAR
General
This blog follows a request to restore the general queue usage and sharing between Atlas and STAR. Its use was discontinued several years back based on several criterion amongst which:
- Atlas was fine with us using their CPUs but refused to mount our disks (at the the PanFS era) and claimed instabilities they cannot risk. We interpreted this as a politically correct way to say "no use" since mounting our disk is a primary requirement for being able to use resources. Beyond this event which killed the use of the general queue, several issues still exists as far a mounting goes:
- Maintaining mount points seem to be a challenge (case and point: grid and rftpexp nodes never seem to have the latest update of the mount points for RHIC)
- Mount points would imply network bandwidth (see next bullet)
- To make use the facility within the network isolation design of the Atlas/RHIC network, additional networking would need to be put in place. This is not currently a priority (priority is to the interconnect between the RHIC farm and its hardware and resolving the 1:8 over-subscription of LAN in the RHIC domain. This project alone has spanned two years consolidation and reshape and is still ongoing)
- The facility is not homogeneous between ACAS and RCAS - the OS upgrade cycles are not the same and from compiler version to CERNLib versions, we do not have the same stack available on both machine. Hence two software stacks would need to be kept for using the Atlas resources.
Benefit analysis
The following graph is a resource usage of the Atlas CPU slots as viewed by Condor from February 5th to April 5th 2010.
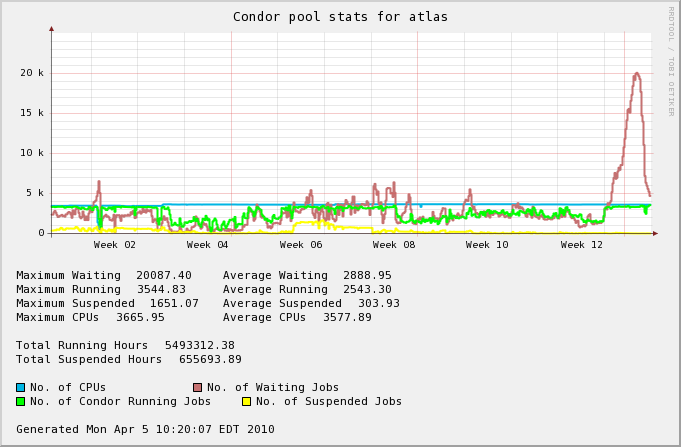
The difference between the average running and the number of CPUs tend to indicate a 1000 CPUs possible under-utilization.
A zoom on the time frame below Week 12 is below and confirm this
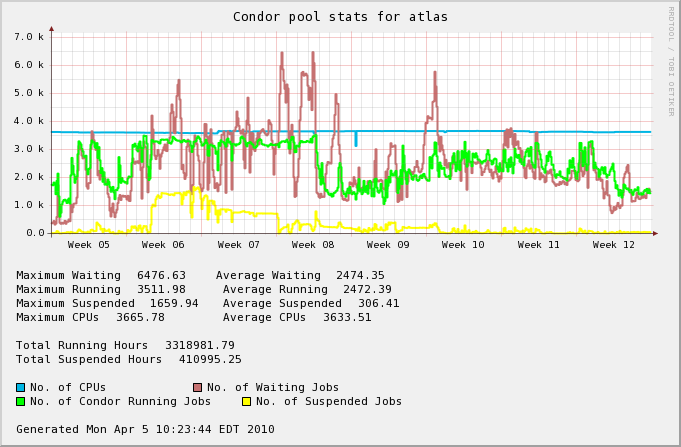
However, observing the queue in the past recent days, the over-subscription of the queue tend to indicate slots would not be available. It is to be noted that the CERN/LHC beam has now started, possibly cuasing a queue fill-up.
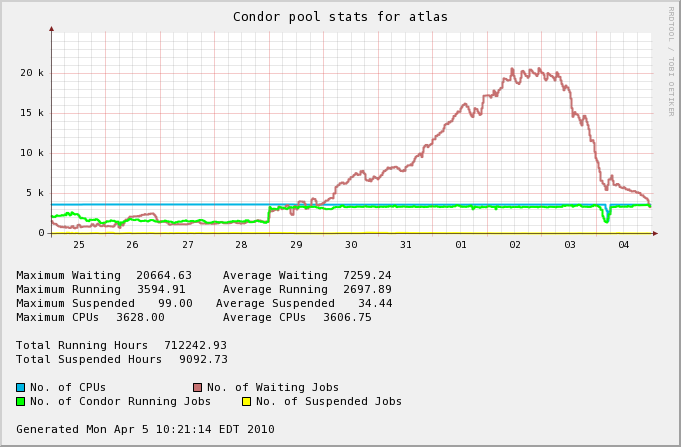
The following statement was sent by Micheal Ernst (facility director for the RACF) upon inquiry (this is an extract of an Email from April 5th 2010, 07:43, Subject =~ m/general queue and cross mounting disks on rhic\/usatlas/)
Let me start with letting you know that there are no CPU resources left at the ACF that could be used by other experiments. Now that the LHC machine is ramping up with stable beam delivery simulation and analysis activities are at a point where ATLAS could easily fill another couple of thousand job slots. I expect this situation to continue and I can imagine that the pressure on the facility will even rise over the next few months.
The status is that we will not push further but watch for the queue usage for possible low-down which would make this investigation and work worthwhile.
Farm shared queue usage
A typical queue sharing usage from the beginning of the year to date (2010/03/06) is as follows:
| Ending On Phenix | On Phobos | On STAR | On Brahms | On Atlas | On RCF | Total | |
| STAR jobs count | 333330 | 71887 | 3332435 | 74580 | 676 | 172902 | 3985810 |
| STAR job %tage | 8.36% | 1.8% | 83.6% | 1.9% | 0.01% | 4.34% |
Average slots available per weeks since
| Date | OS = Opened slots (<CPU> - <running>) |
occupancy Number > 100 indicates the |
Graph |
|---|---|---|---|
| April 1st - April 15th | 210 (05.8%) | 103% | 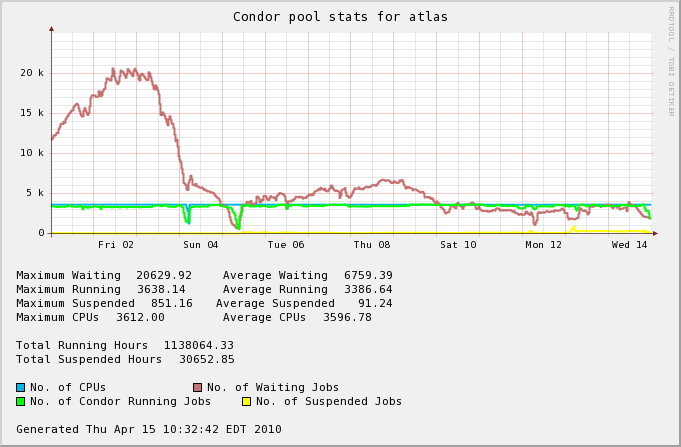 |
| April 16th - April 30th | 167 (04.7%) | 94.6% | 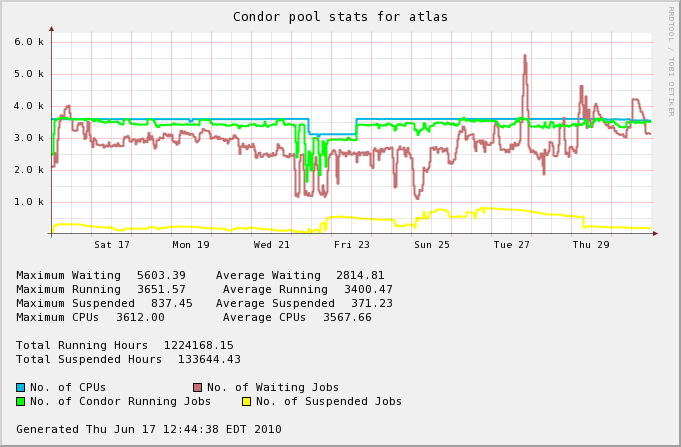 |
| May 1st - May 15th | 266 (07.4%) | 101% | 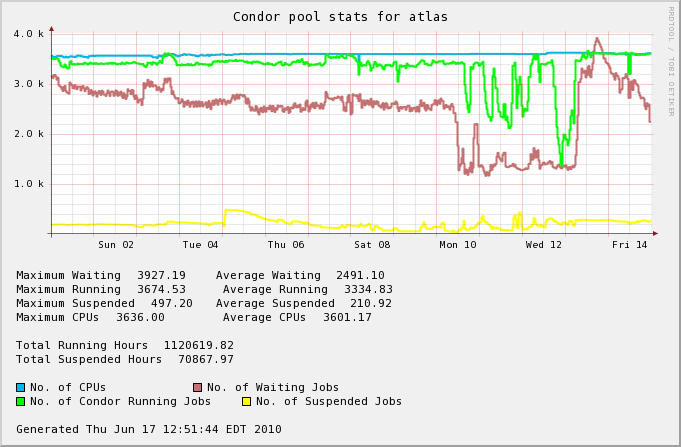 |
| May 15th - May 31st | 419 (11.5%) | 108% | 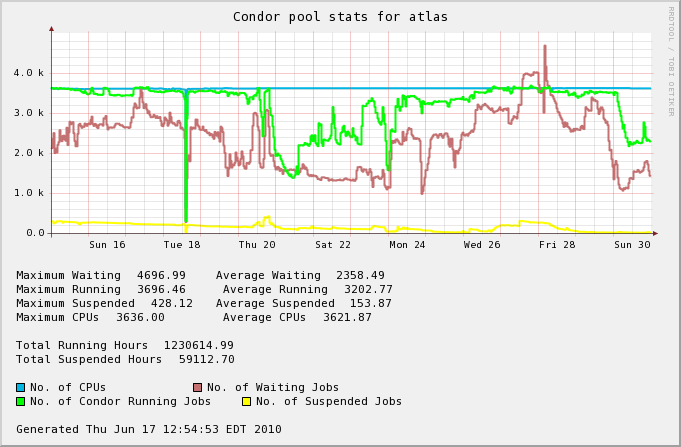 |
| June 1st - June 15th | 300 (08.5%) | 105% | 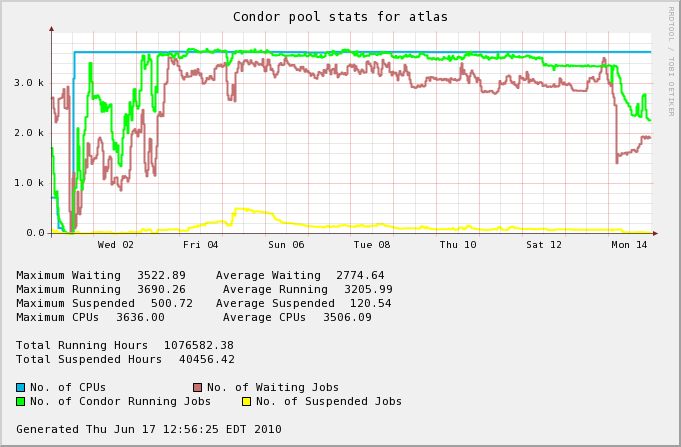 |
| June 15th - June 30th | ... | TBC |
Groups:
- jeromel's blog
- Login or register to post comments