Last modified
Last
modified
Basic purpose & Established procedure when a problem occurs :
Now that you already know the summary, let's go into the details ...
During normal business hours (8 AM - 4 PM), the RCF staff members are always on shift.The next shift period goes from 4 PM - 12 AM, which is the responsibility of an RCF operator. The operator name can be found on the RCF Shift Monitor page .
During a run, the time between 12:30 AM - 8:30 AM belongs to a STAR OR a PHENIX shift person on alternating weeks. On BNL lab holidays, STAR or PHENIX is responsible for shifts during the entire day. To see who is responsible for the overnight RCF Monitoring shift, use the Shift Calendar .
In the case of STAR, the Quality Assurance Monitor shift person is responsible for the RCF monitoring.
Summary
Here is the schedule of RCF shifts for the week. Please check first the Shift Calendar , when you start taking the Quality Assurance Monitor & Run Time Assistant shift.
In the following sections, we will explain how to monitor the RCF and what you should do.
The STAR RCF monitoring shift person is required to carry the RCF phone-list above onllinux2 in the STAR counting house. A second list is taped to the STAR Shift Leader's desk. If you do not find this list, Email me immediately. If anyone from the 4 experiments experiences a problem with the RCF, the RCF Monitoring Shift person should call the appropriate expert. The shift person is not required nor qualified to fix the problem. The main responsibility of the shift person is to assess the severity of a problem and decide whether to call the appropriate RCF expert or to file a CTS ticket.
The shift person is required to monitor the data transfer rate to HPSS from the counting house.
The counting house monitoring shifter should be aware of the data transfer to HPSS.
Only problems affecting data-taking justify a call to the expert in the middle of the night.
(1) Mandatory
Monitoring
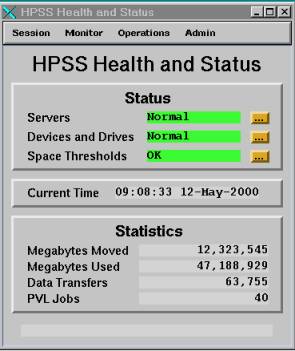
1-1. HPSS Monitoring
HPSS Check list for the shifter
If
you find a problem as described in the above check-list
OR
If you receive a call from another experiment reporting similar problems
Figure 1. HPSS Health and Status monitor GUI.
On-call person for HPSS problem
Click Current HPSS on call person to see who is covering for HPSS now. The office and beepr numbers summary is indicated above.
|
Razvan Popescu |
X5806, pager: 877-546-9067 |
|
John Riordan |
x7201, pager: 877-526-2715 |
|
Ognian Novakov |
X2813, pager: 877-451-1920 |
|
Grace Tsai |
X3905, pager: 877-629-4452 |
How to setup HPSS monitoring software at the STAR counting house. (not necessary to read, if HPSS GUI has already been set up)

Figure
2. The Sammi Login window
Here are a list of links toward several HPSS related monitoring tools and interfaces.
1-2. Network Monitoring
Network Monitoring
It is important to monitor the network traffic as a network problem may be the reason for a broken data flow / data sinking. In other words, if data sinking stops from the counting house point of view, you MUST determine if the problem is related to HPSS (see section 1-1) or network related.
There are several tools helping to monitor the network traffic. All links provided above may be found on the RCF Network Infrastructure page. We will describe what we believe is important for STAR.
The RCF Gigabit snapshot page is a complex graph showing the overall network layout at the RCF. On top of it, the purple boxes connections to the first green box labeled SW1 shows the traffic between the different counting houses and the main switch SW1. The green number displayed below the purple [ STAR ] box is the number for STAR. If 0, there may be a problem OR STAR is not sinking data ... Now, following the traffic (black line), the next number appears below SW1 on the way toward SW6 ; this number measures the internal traffic rate. Finally, the last relevant number appears in the corner of the connection SW6 to rmds08. This is our final data sinking rate to HPSS . Numbers are integrated transfer rate in MB/sec ... Again, ff any of those numbers goes to 0 it may be the sign of a network problem or the fact that there is really no activity. This complicated graph however can be analyzed in more detailed using the following
(2) Non mandatory monitoring
2-1. Servers Monitoring
The status of monitored machines can be checked from here. Figure 3 shows the snapshot of the status of monitored machines. You can check the current status of the ssh gateway servers, FTP servers, NFS servers, DNS/NIS servers and mail servers. In this status monitor, green signal indicates OK, yellow is the warning sign and red is a failure sign. Failure (in red) on one of the RMINE (NFS server) machines does not warrant a call to the expert in the middle of the night.
A CTS ticket could be filled. However, RNIS (NIS server) machines and ssh gateway machines (RSSH) are critical and DO warrant a late-night call during data-taking. Call the appropriate RCF responsible person (see below). The hard copy of list of RCF staff's home phone number should be available at the control room. If you cannot find this list, please send me (J.Lauret) a note ASAP and I will provide it.
On-Call RCF persons for RNIS and SSHGW problem
|
Maurice Askinazi |
x2159, pager: 877-450-3915 |
|
Shigeki Misawa |
x2635, pager: 877-601-4879 |
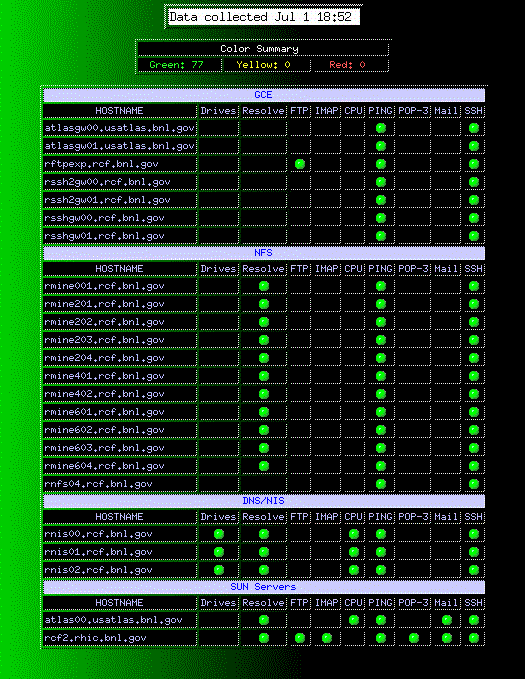
Figure 3. Status of monitored machines display.
2-2 Instructions for CAS and CRS node monitor
|
Subsystem |
Name |
Office Phone |
Pager |
|
General |
RCF Operator |
x5480 (4:00pm - 00:00am) |
NA |
|
RNIS and RSSH |
Maurice Askinazi |
x2159 |
877-450-3915 |
|
Shigeki Misawa |
x2635 |
877-601-4879 |
|
|
Network |
Terry Healy |
x4199 |
NA |
|
HPSS |
Razvan Popescu |
x5806 |
877-546-9067 |
|
John Riordan |
x7201 |
877-526-2715 |
|
|
Ognian Novakov |
x2813 |
877-451-1920 |
|
|
Grace Tsai |
x3905 |
877-629-4452 |
Paging RCF Personnel
Other useful Links for the online QA shifter