KFParticle Vertex Finder
Summary
J. Lauret, V. Perevoztchikov, D. Smirnov, G. Van Buren, J. C. Webb
The Goal
- Re-evaluate performance of the KF and PP vertex finders by reproducing results reported in 2012 by Amilkar/Jonathan/Yuri (see KVF vs PPV, 2012)
- Conclusions from that study:
- Overall the KFV primary vertex finding efficiency is somewhat better than that of PPV for the W signal with zero-bias pile-up
- In case of clean simulated W-boson signal (no pile-up), PPV is better in finding the right vertex. In other words, KFV efficiency does not degrade as much as the PPV one in noisy environment
- There is an indication that KFV also provides better than PPV vertex efficiency when the vertex rank is taken into account
- TMVA ranking scheme further significantly improves primary vertex finding efficiency
- Unaddressed issues
- Statistically inconsistent samples make it hard to compare the efficiency curves and draw conclusions
- High impurity of KFV and TMVA ranking schemes at low vertex track multiplicities may lead to selection of fake verticies in some analyses
- Conclusions from that study:
The Strategy (this study)
- Data. We started KFV evaluation by performing the standard W analysis of the spin PWG (Jinlong)
- The W analysis was carried out using a sub-sample reconstructed using the KFV finder. The only requirement on the vertex to have a positive rank (standard for PPV) was dropped
- The number of final selected signal events (with identified primary vertices matching a high-E tower) went down by 10% comparing to the PPV finder
This is inconsistent with 2012 pile-up studies but consistent with expectations from clean MC W-boson samples
- Simulation. We proceeded with an MC study similar to the 2012 one
(Due to lost data samples and lack of complete documentation from the 2012 study it is impossible to exactly reproduce the original plots)- To get as close as possible to the reported results we use the following setup:
- The code from the HEAD of CVS as of October, 2015 (that includes KF, Sti, and other event reconstruction code)
- For the primary vertex we simulate W events with the setup used by the Spin PWG (Jinlong). Run 13 geometry
- For pile-up embedding we use Run 13 zero bias data (Currently ~50k events from day 150 only)
- The code and scripts recovered from various sources has been collected in the following repository: https://github.com/star-bnl/star-travex
...a tag will be added when ready to fix the code
- In this simulation-based study we use the same vertex finding efficiencies as in the 2012 study. They are defined as:
- The denominator is common and filled with the number of primary MC vertices having tracks with TPC hits >= 15
- The Overall Efficiency is calculated by counting the number of reconstructed vertices (regardless of their rank) which have been matched to the primary MC vertex (based on idTruth == 1). In other words, the efficiency gives the probability of the vertex finder to reconstruct the true MC vertex in the event
- The Max Rank Efficiency is similar to the Overall Efficiency but only for the vertices having the maximum rank
- The Impurity counts the maximum rank reconstructed vertices which do not match the primary MC vertex
- To get as close as possible to the reported results we use the following setup:
Conclusions and Findings
- Without pile-up
- PPV outperforms KFV in finding the primary vertex. KFV has lower efficiency of finding the correct primary vertex with fewer tracks attached to it
- However, KFV show better efficiency for finding the primary vertex when the ranking is used. The highest rank reconstructed vertex is more likely to be the true primary vertex
(Note: PPV was not designed to rank the found vertices properly other than assigning a negative rank to likely pile-up vertices)
- With pile-up
- In the new W-boson embedding sample (2013) we find significantly better vertex finding efficiencies for KFV over PPV. This is true for both overall finding and ranked vertex efficiencies
- Finding #1: The impurity is still high and is something to worry about for low multiplicity vertices where the analyzer with a high probability may select a fake vertex if rely on the KFV ranking scheme
- Finding #2:
- PPV internaly constraints the number of verticies released to the user based on an early ranking cuts. It means that if the ranking is not optimized there is a good chance to miss the true primary vertex
- PPV shows the same overall vertex finding efficiency as KFV (86% vs 87%) when the above constraint is removed
- Data
- The Spin PWG reports a 10% lower W selection efficiency with KFV vs PPV
- The Spin PWG reports a 10% lower W selection efficiency with KFV vs PPV
- Finding #3:
- As we found out the calculation of the Impurity for ranked vertices does not correspond to the original definition. We corrected it, and as expected the following now holds true: Impurity = (1 - Max Rank Efficiency)
Recommendations
- Investigate if a procedure for running vertex finders as afterburners on muDst files can be established (given global tracks and their errors are saved)
November 18, 2015
The hard coded limit on the number of "bad" vertices has been raised from 5 to 150 in PPV
 |
.png) |
November 12, 2015
Here we looked at a few basic distributions for event observables to see if the embedding sample is consistent with the data. The intention is to understand why PPV and KFV relative performance is reversed in embedding and data samples.
| PPV Embedding | PPV Data | KFV Embedding | KFV Data |
|---|---|---|---|
November 11, 2015
In this test we made sure to use the same primary vertex cuts in PPV finder as in the original W analysis. As the result the average efficiency increased from 0.62 to 0.76. It is still lower than the KFV efficiency of 0.81 (0.87) (see below0
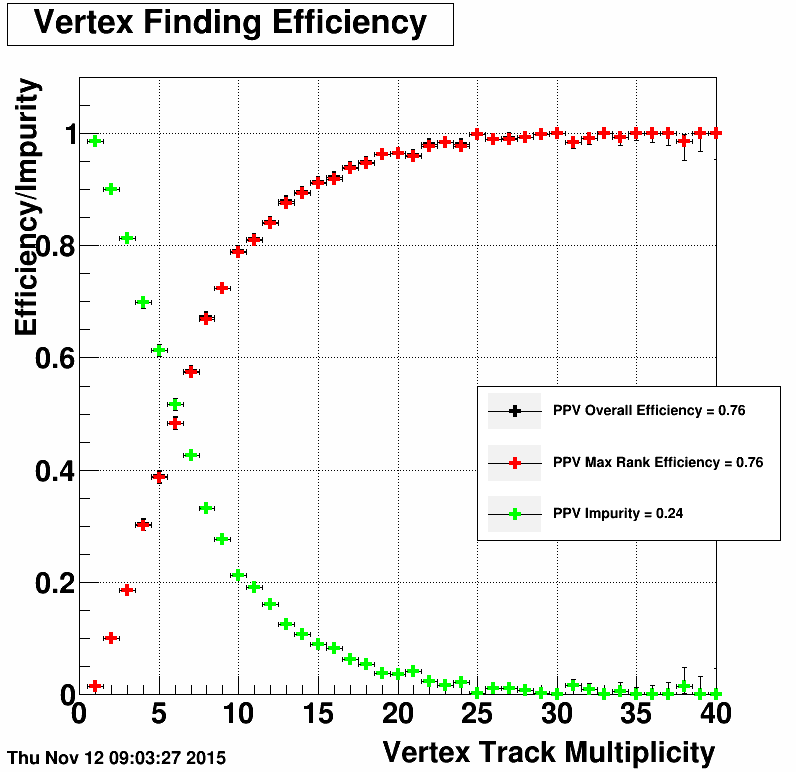 |
|
November 10, 2015
In the code calculating the impurity, reconstructed verticies which do not have a matching MC vertex were incorrectly ignored from the total count. After fixing this the "red" and "green" curves now add up to 1 as expected.
PPV (left) vs KFV (right)
.png) |
|
November 5, 2015
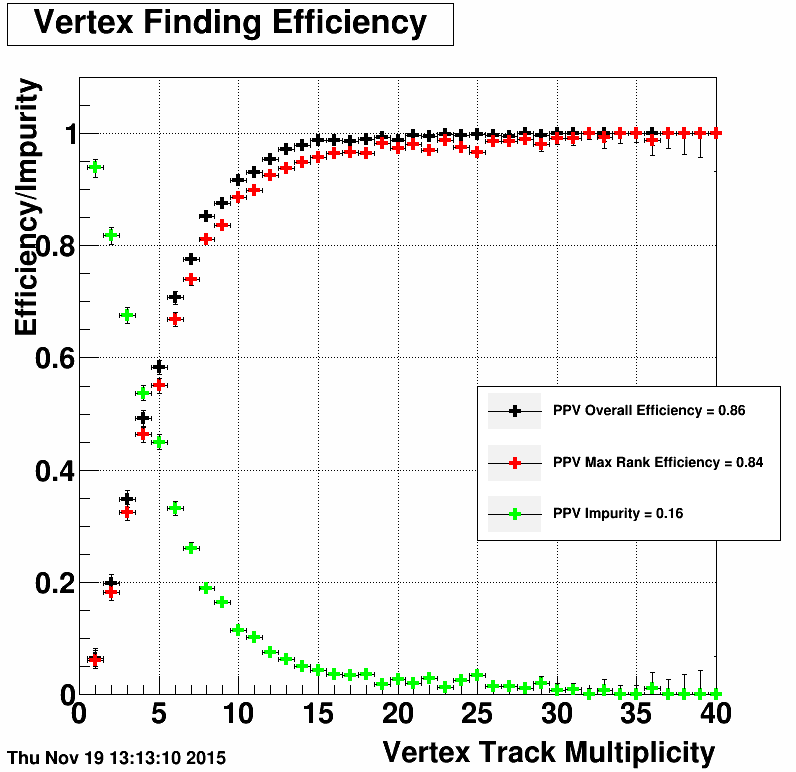
Removed requirement on the minimum value of the Max Rank vertex rank (<0). PPV (left) vs KFV (right)
.png) |
.png) |
November 1, 2015
Results from the new 2013 W embedding samples: PPV (left) vs KFV (right)
.png) |
.png) |
The file list used for this embedding sample is: filelist_wbos_embed.txt
October 6, 2015
The following plots show vertex finding efficiencies for PPV (left) and KFV (right) as determined from a 50k event sample of Pythia simulated W-boson events without pileup located at:
/star/institutions/bnl_me/smirnovd/public/w_sim_nopileup_fzd/ /star/institutions/bnl_me/smirnovd/public/w_sim_nopileup_ppv/ /star/institutions/bnl_me/smirnovd/public/w_sim_nopileup_kfv/
The following options were used to reconstruct the samples
BFC_OPTIONS="fzin tpcRS y2014a AgML pxlFastSim istFastSim usexgeom FieldOn MakeEvent VFPPVnoCTB beamline Sti NoSsdIt NoSvtIt StiHftC TpcHitMover TpxClu Idst BAna l0 Tree logger genvtx tpcDB bbcSim btofsim tags emcY2 EEfs geantout evout -dstout IdTruth big clearmem" BFC_OPTIONS="fzin tpcRS y2014a AgML pxlFastSim istFastSim usexgeom FieldOn MakeEvent KFVertex beamline Sti NoSsdIt NoSvtIt StiHftC TpcHitMover TpxClu Idst BAna l0 Tree logger genvtx tpcDB bbcSim btofsim tags emcY2 EEfs geantout evout -dstout IdTruth big clearmem"
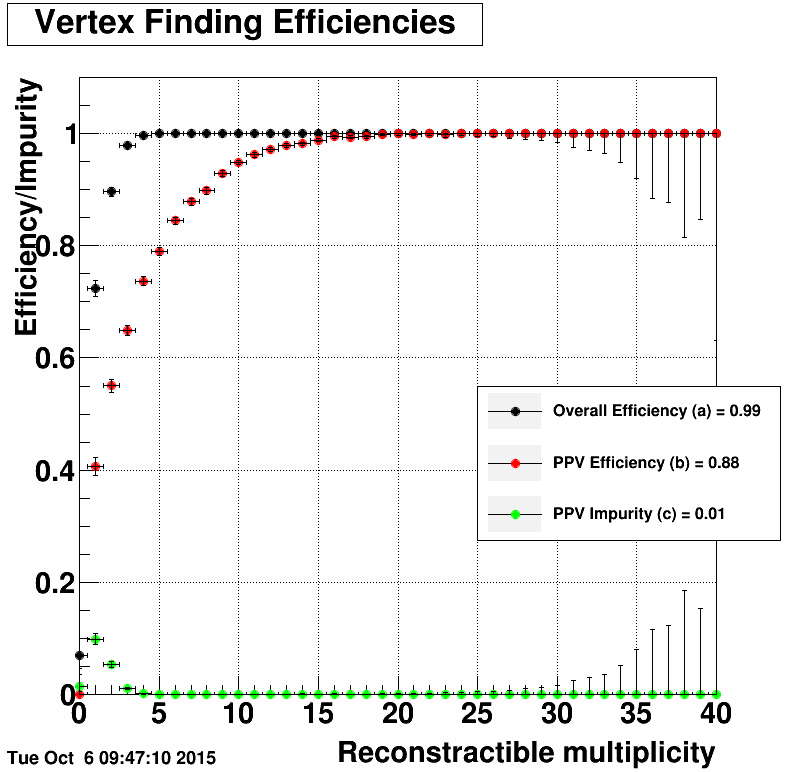 |
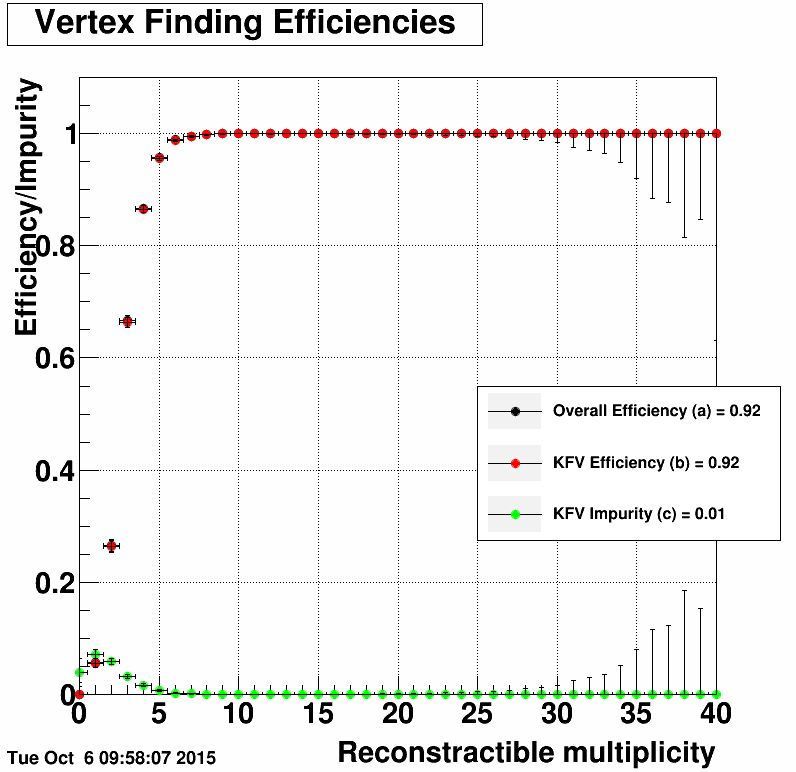 |
September 24, 2015 Updated: October 1, 2015
The following plots show vertex finding efficiencies for PPV (left) and KFV (right) as determined from a 50k event sample of Pythia simulated W-boson events without pileup located at:
/star/institutions/bnl_me/smirnovd/public/amilkar/MuDst/ /star/institutions/bnl_me/smirnovd/public/amilkar/PPV2012/
The distribution for KFV is somewhat comparable to the 2011 and 2012 results shown below
The PPV case was reconstructed without the 'beamline' option.
.png) |
.png) |
September 14, 2015
The following plot with vertex finding efficiencies (default = PPV) was created using the refactored code from Amilkar (github.com/star-bnl/star-travex)
Here I used 10k events from Run 13 W-boson Pythia embedding simulation from Jinlong located at:
/star/data19/wEmbedding2013/pp500_production_2013/Wminus-enu_100_20145001/P14ig.SL14g/2013/
Comparing to the 2011 and 2012 results shown below the efficiency appears to be slightly better for lower multiplicity vertices. The overall average efficiency is slightlyt higher 0.50 vs 0.46
.png) |
August 05, 2015
What We Know
- Recent studies
- KFV is ~10% less efficient than PPV in finding the primary vertex as established by the STAR W analysis (Jinlong Zhang, You do not have access to view this node)
- The jet spin analysis seems to be insensitive to the choice of VF... Both PPV and KFV show comparable results (Zilong Chang)
- Some details below
- Past studies (Amilkar/Jonathan/Yuri, 2012)
- p+p 200GeV W simulation without pileup
Black points: MC vertex was found;
Red points: MC vertex matched the highest rank vertex;
Yellow points: MC vertex matched the highest TMVA rank vertex
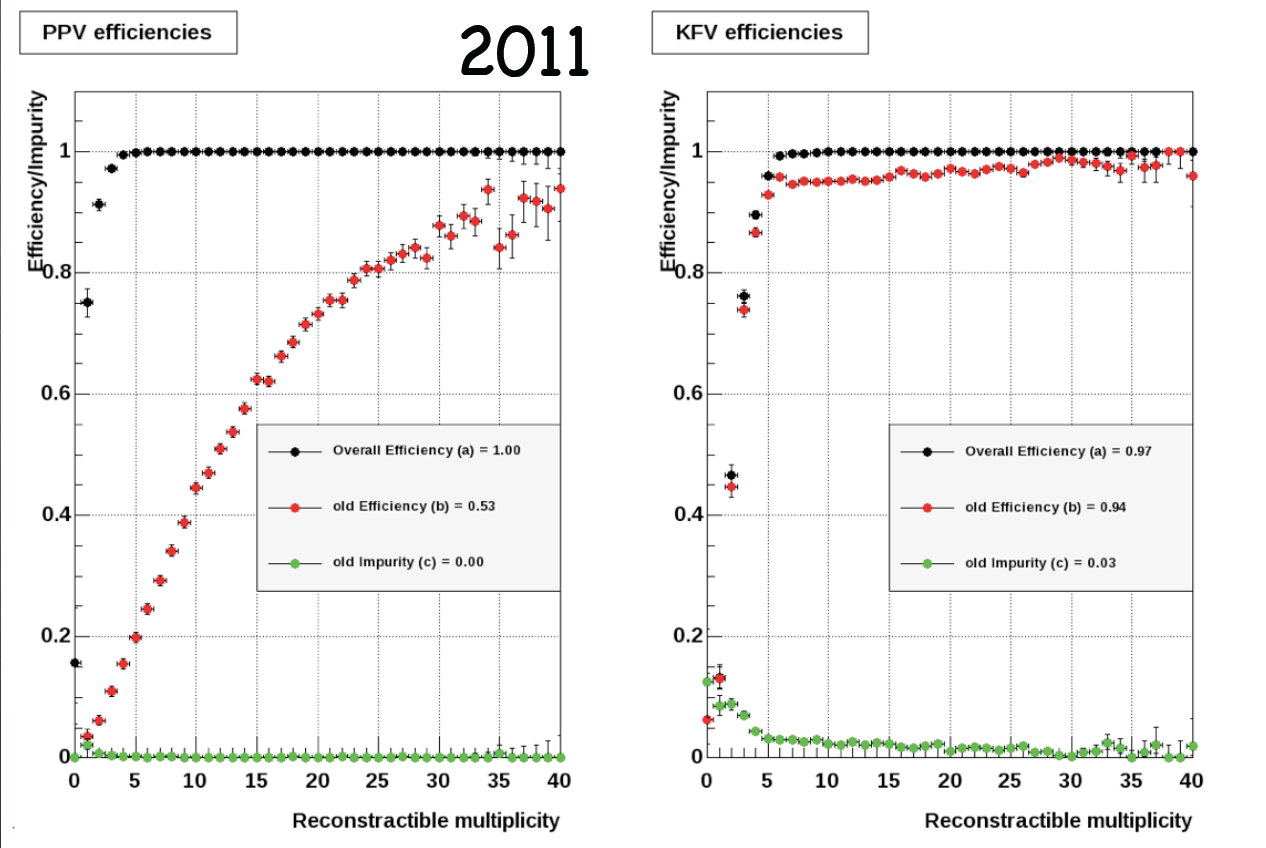
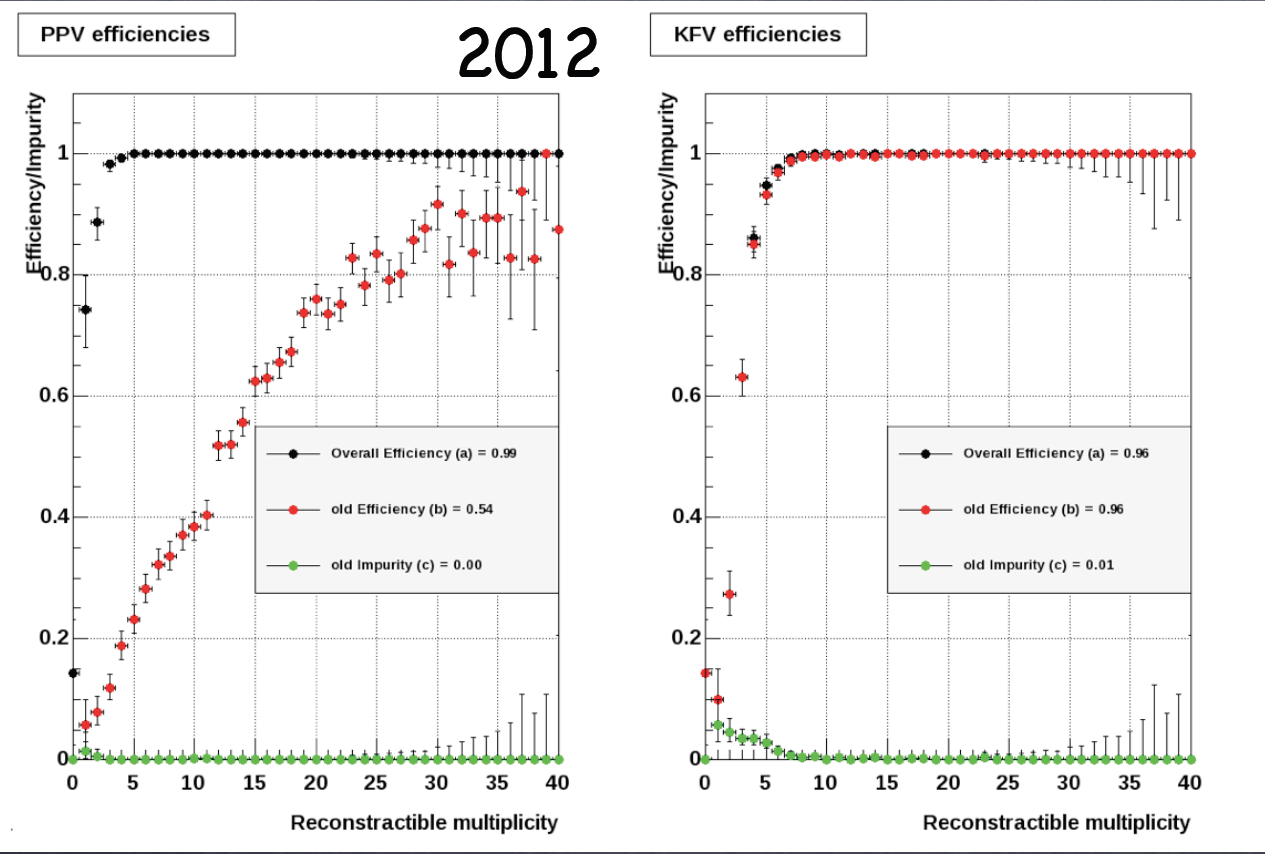
Questions:
What exactly is the difference between 2011 and 2012 years?
Why KFV shows significantly different efficiency for 2011 and 2012?
From the above right handside plots: Does it actually mean that the KFV ranking works and works better than the PPV one?
KFV does give lower efficiency for low multiplicity vertices than PPV But this is with no pileup! Could this explain the 10% loss in the W efficiency? See below for the case with pileup - p+p 200GeV W simulation with pileup: 2011 and 2012 embedding
Black points: MC vertex was found;
Red points: MC vertex matched the highest rank vertex;
Yellow points: MC vertex matched the highest TMVA rank vertex
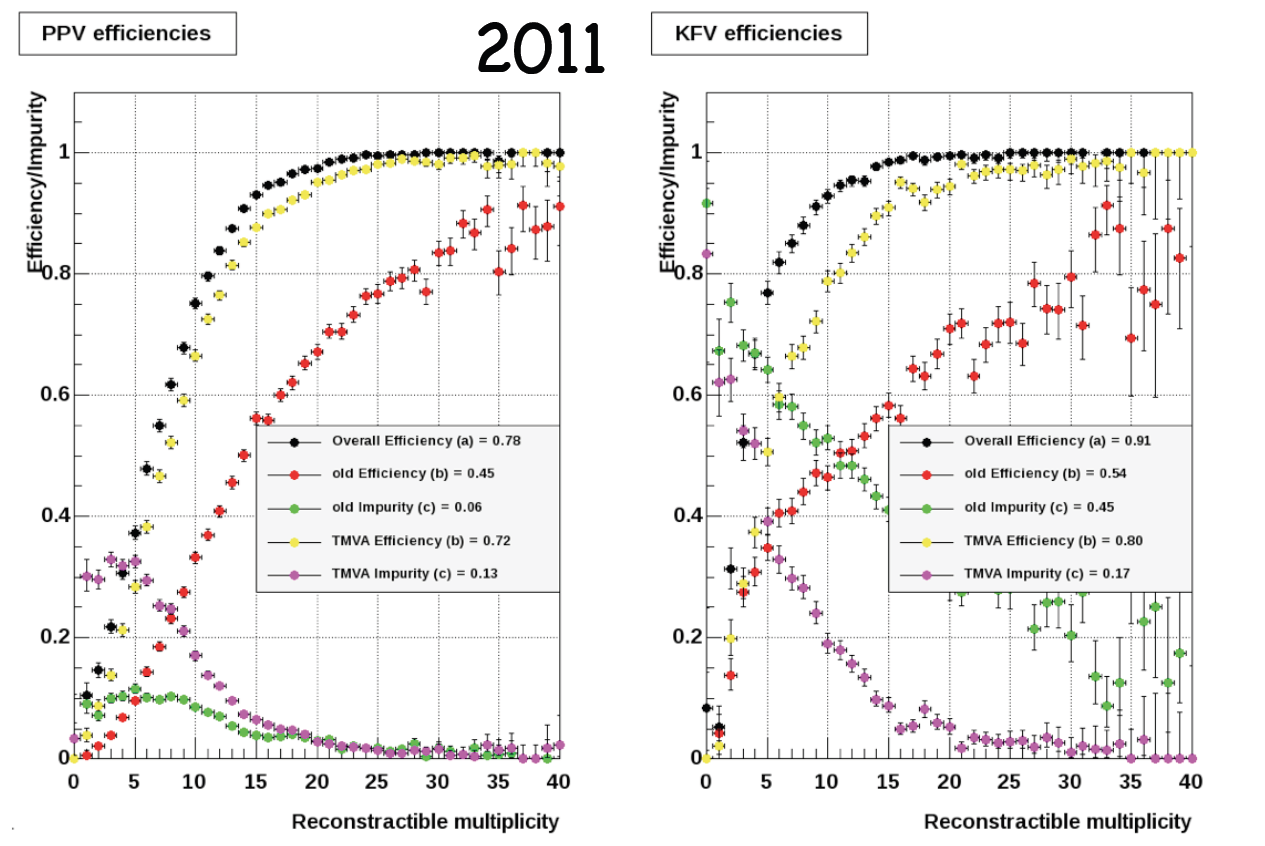
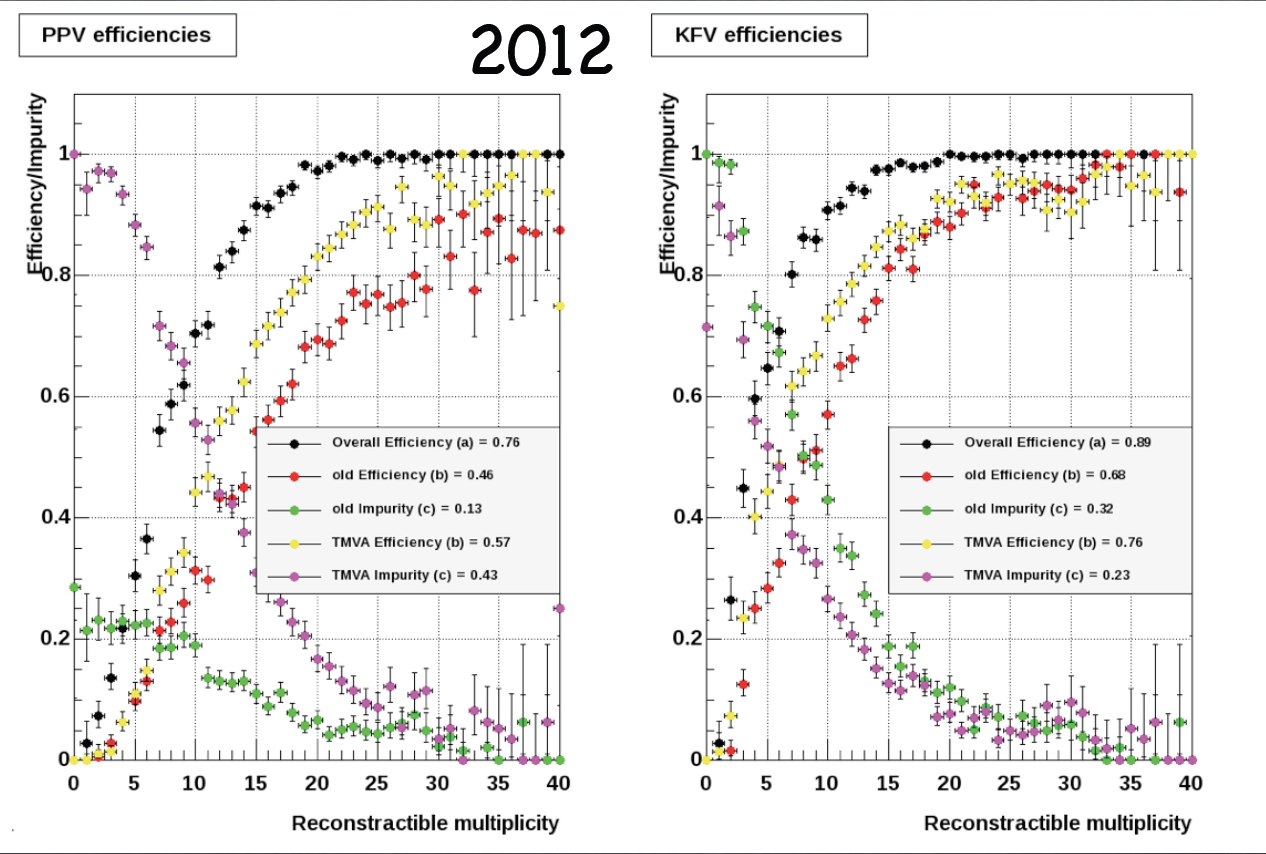
Questions:
From the above plots it does look that KFV also outperforms PPV even at low multiplicities with pileup.
TMVA ranking is better than default one?
- p+p 200GeV W simulation without pileup
- Heavy flavor analysis uses KFParticle code to refit the primary vertices found by their default vertex finder (MinuitVF?)
Where we are
- Reproduce the results presented by Amilkar/Jonathan/Yuri in 2012
- We established a repository to collect the code needed for this study
https://github.com/star-bnl/star-travex- Amilkar has provided a few macros to create trees for TMVA (Many thanks!) but the code to create the efficiency histograms seems to be missing
- Use the same data set from 2012 or create a new one using recent library/data for embedding (I think whichever is easier/readily accessible)
- The recent W embedding request is still being established (Grant Webb, KFParticle Vertex Finder Production Request )
- We established a repository to collect the code needed for this study
- In addition to reproducing/confirming the results of the 2012 study we can do a more direct comparison
- We can build this functionality in star-travex (some basic histograms already available)
- This study could confirm the results from the evaluation with the W analysis but without the overhead of the analysis
- An event-by-event comparison seems to be most attractive
July 22, 2015
KFParticle Vertex Finder Evaluation with W Analisys
For the KFV finder test we used the W analysis performed on the p+p 500 GeV data sets reconstructed using the PPV and KFV finders correspondingly:/star/data23/reco/pp500_production_2013/ReversedFullField/P15ic_VFPPV/2013/ /star/data26/reco/pp500_production_2013/ReversedFullField/P15ic_KFvertex_BL/2013/More details can be found in the following email from Lidia:
http://www.star.bnl.gov/HyperNews-star/protected/get/starprod/648/1/1/1/1/1/1/3/1.html
The summary: We compared the output yields of the W analyses and found that KFV finds about 10% less W events than the PPV finder. Although, in the standard W analysis (using PPV) the considered vertices required to have a positive rank we removed that requirement and let the framework to consider ALL vertices found by KFV
References:
PPV and KFVertex performance comparison based on simulation for y2011 & y2012 pp200 with pile-up - Amilkar/Jonathan/Yuri
- Printer-friendly version
- Login or register to post comments